Die fortschreitende globale Vernetzung beginnt sich aus dem akademischen und industriellen Umfeld in die privaten Haushalte fortzusetzen. Damit wird der bisher unidirektionale, zeitlich gebundene Informationsfluß heutiger Broadcast-Medien durch interaktive Medien ersetzt. Letztere sind im Begriff, die Informationsgesellschaft nachhaltig zu revolutionieren, wobei besonders das World-Wide Web [Berners-Lee, 92] dieser Entwicklung Vorschub leistet. Die Durchdringung der Gesellschaft mit Netzwerkdiensten geht einher mit einer ständig steigenden Anzahl vor allem computerunerfahrener Anwender. In gleichem Maße wächst der Umfang und die Vielfalt der über das Netzwerk verfügbaren Informationen und Objekte.
In diesem Umfeld haben Namen die Aufgabe, dem Anwender eines Systems das Auffinden und Manipulieren von Objekten, wie z.B. Rechner, Dienste, Dokumente, Speicherbereiche, Umgebungsvariablen, Bildschirmfenster, Prozesse oder Netzwerkverbindungen, zu erleichtern. Die Notwendigkeit von Namen in Rechnersystemen liegt darin begründet, daß das menschliche Gedächtnis Namen, die Wörtern einer natürlichen Sprache entsprechen, wesentlich besser behält als systemnahe Bezeichner. Namen existieren in Form strukturierter Zeichenketten mit eigener Mnemonik und bieten dem Benutzer die Abstraktion vom zugrundeliegenden Objekt.
Im einzelnen dienen Namen der
• Erklärung,
• Identifizierung und
• Lokalisierung eines Objekts.
Die Verwaltung von Namen übernehmen Namensverwaltungen wie das Domain Name System (DNS) [Mockapetris, 83]. Deren primäre Aufgabe ist es, Namen von Objekten auf Adressen und Identifikationen abzubilden, die Objekte eindeutig kennzeichnen und für deren Zugriff benötigt werden.
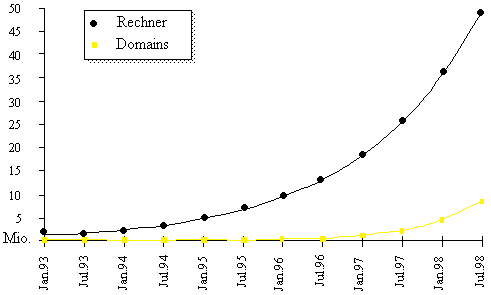
Abbildung 1.1: Prognostizierte Entwicklung von Rechnern und Domain Namen im Internet
In Zusammenhang mit der Verbreitung globaler Netzwerke sind folgende Entwicklungen zu beobachten, die Auswirkungen auf globale Netzwerkdienste haben:
· ständig steigende Anzahl benannter Objekte: Diese Entwicklung (vgl. Abbildung 1.1) stellt nicht nur hohe Anforderungen an die Skalierbarkeit globaler Namensverwaltungen, sondern erfordert zudem einen immensen Administrationsaufwand, so daß die Aktualität von Namensverzeichnissen oft nicht gewährleistet ist.
· ständig steigende Anzahl comuterunerfahrener Anwender: Die Beschreibung von Objekten durch Namen ist meist sehr subjektiv und kann nicht allen Anwendern gleichermaßen gerecht werden. Anwender müssen daher die Möglichkeit besitzen, sich ihre individuelle Sicht auf den Namensraum und die für sie relevanten Objekte zu schaffen.
· zunehmende Diversität benannter Objekte: Die Diversität benannter Objekte erfordert eine flexible Möglichkeit zu deren Beschreibung.
· zunehmende Dynamik und Mobilität benannter Objekte: Die Dynamik globaler Netzwerkdienste bewirkt, daß die Objekte im Netzwerk ständigen Veränderungen unterworfen sind. Diese Entwicklung impliziert auch Änderungen der an Objekte gebundenen Namen.
Die vorliegende Arbeit präsentiert Konzepte zur selbständigen Konfigurierung des Verwalternetzes und zur dynamischen Verwaltung globaler Namensräume nach dem Prinzip der Kontextbildung. Die Forderung nach Individualität des Namensraums, die Diversität der benannten Objekte und die Aktualität der Namensverzeichnisse finden dabei besondere Berücksichtigung.
1.1 Anforderungen an die globale Namensverwaltung
Die zunehmende Integration lokaler Netzwerke in öffentliche, weltumspannende Netze läßt auch die Anforderungen an die Funktionalität der Namensdienste ständig wachsen. Globale Namensverwaltungen müssen dabei gleichermaßen den Forderungen nach Effizienz, Zuverlässigkeit und Sicherheit lokaler Anwendungen als auch den administrativen Erfordernissen verteilter Anwendungen entsprechen. Folgende allgemeine Anforderungen und Entwurfsziele für globale Namensdienste lassen sich identifizieren:
· Anforderungen an Namen:
·
Eindeutigkeit: Vollständig spezifizierte Namen müssen
Objekte eindeutig identifizieren. Ein Objekt kann jedoch mehrere Namen tragen.
·
Universalität: Die dem Anwender zur Verfügung stehenden
Namen müssen ein breites Spektrum von Objekten unterschiedlichster Eigenschaften
benennen.
·
Ortsunabhängigkeit und Transparenz: Namen müssen ortsunabhängig sein und den
Transparenzanforderungen eines verteilten Systems (vgl. Abschnitt 1.1.3) genügen.
·
Individuelle Anpassungsfähigkeit: Anwender sollen Namensräume selbständig
administrieren und logische Verzeichnisse nach beliebigen Kriterien anlegen
können.
·
Flexibilität der Namensanfrage: Anwender sollen generische und attributierte
Namen verwenden können, um Objekte zu lokalisieren und zu identifizieren.
· Anforderungen an die Namensverwaltung:
·
Effizienz: Die
Registrierung und insbesondere die Auflösung globaler Namen sollte schnell
geschehen, da Anwendungen u.U. blockieren, bis die Namensoperation abgeschlossen
ist. Ferner sollte der Verbrauch an Ressourcen wie Netzwerkbandbreite,
CPU-Zeit und Speicher niedrig sein, da in globalen Namensverwaltungen sehr
viele Namen verwaltet werden müssen und eine große Anzahl von Anfragen zu
bewältigen ist.
·
Skalierbarkeit: Eine globale Namensverwaltung muß sowohl den
Anforderungen, die sich aus einer zunehmenden räumlichen Ausdehnung ergeben, als
auch einer steigenden Anzahl von Benutzern und verwalteten Namenseinträgen
gewachsen sein.
·
Selbständige Konfigurierung und
Administration: Die
Namensverwaltung soll den Anwender weitgehend von Konfigurierungs- und
Administrationsaufgaben befreien.
·
Langlebigkeit des Systems: Sowohl die globale Namensverwaltung als auch
der zugehörige Namensraum müssen für eine lange Lebensdauer konzipiert sein,
in der sie vielen Änderungen unterworfen sind.
· Sicherheitsanforderungen:
·
Hohe Verfügbarkeit und Fehlertoleranz: Viele Dienste sind von der Verfügbarkeit
der Namensverwaltung inhärent abhängig. Partielle Ausfälle der Namensverwaltung
dürfen daher nicht die gesamte Namensverwaltung betreffen.
·
Autorisierung: Die Ausführung von Namensoperationen ist
nicht jedem Anwender in gleichem Maße gestattet.
Nachfolgend werden die soeben aufgestellten Anforderungen für die globale Verwaltung von Namen eingehender diskutiert.
1.1.1 Eindeutigkeit von Namen
Eine grundlegende Anforderung an Namen ist Eindeutigkeit. Um ein Objekt eindeutig durch seinen Namen identifizieren zu können, muß der Name eindeutig sein, d.h. derselbe Name darf keinem weiteren Objekt zugeordnet sein. Dem gegenüber kann ein Objekt durchaus mehrere Namen tragen, ohne daß es dabei zu Konflikten kommt.
|
212155 |
www |
3267 |
dns |
2147 |
mercury |
1545 |
home |
1265 |
newton |
|
27758 |
mai |
2802 |
smtp |
2125 |
gate |
1544 |
apollo |
1218 |
thor |
|
27292 |
ftp |
2796 |
server |
2109 |
alpha |
1538 |
eagle |
1209 |
merlin |
|
25649 |
ns |
2679 |
venus |
1925 |
saturn |
1532 |
pc |
1203 |
beta |
|
9861 |
user |
2644 |
cisco |
1914 |
orion |
1524 |
neptune |
1196 |
homer |
|
7782 |
router |
2486 |
test |
1683 |
iris |
1490 |
pop |
1193 |
web |
|
6983 |
news |
2431 |
pluto |
1672 |
bbs |
1393 |
hermes |
1165 |
athena |
|
5049 |
gw |
2414 |
mars |
1622 |
admin |
1378 |
demo |
1151 |
proxy |
|
4737 |
gateway |
2354 |
zeus |
1598 |
gopher |
1315 |
gatekeep |
1142 |
falcon |
|
4616 |
mailhost |
2237 |
jupiter |
1557 |
mac |
1293 |
phoenix |
1122 |
earth |
Tabelle 1.1: Die fünfzig häufigsten Host Namen (ohne Namen wie pc01, mac5, etc.), Stand 6.96
Namen eines Namensraums müssen jedoch nicht notwendigerweise immer global eindeutig sein. Tabelle 1.1 zeigt die im Internet global am häufigsten verwendeten Namen für Rechner. Dabei wird deutlich, daß es mit zunehmender Zahl von Rechnern ständig schwieriger wird, global eindeutige und zugleich aussagefähige Namen zu vergeben. Die Eindeutigkeit von Namen kann jedoch durch die Angabe von Gültigkeitsbereichen (Kontexten) für Namen relativiert werden. Innerhalb eines gegebenen Kontexts sollten verschiedene Objekte jedoch stets verschiedene Namen tragen, um die eindeutige Identifizierung zu ermöglichen. Partielle, unvollständig spezifizierte Namen können durchaus eine Gruppe von Objekten bezeichnen, insbesondere dann, wenn Objekte durch attributierte oder generische Namen identifiziert werden.
1.1.2 Universalität von Namen
Hauptaufgabe einer Namensverwaltung ist die Bereitstellung syntaktischer Namen für Objekte unterschiedlicher Granularität, Lebensdauer, Verteilung und Mobilität. Um ein breites Spektrum von Objekten in globalen verteilten Systemen benennen zu können (Diversität) ist eine flexible syntaktische Struktur von Namen und ihre universelle Verwendbarkeit gefordert.
Dabei sollte für alle Arten von Objekten eine einheitliche Syntax der Namen gegeben sein (Namenstransparenz), die sämtliche Eigenschaften eines Objekts erfassen kann. Um sowohl für Endanwender als auch für Administratoren und Programmierer bedeutungsvolle Namen für Objekte vergeben zu können, die vom Namen auf die Art oder den Zweck eines Objekts schließen lassen, sollte insbesondere keine Beschränkung der Länge von Namensteilen, wie beispielsweise bei DOS-Dateinamen bestehen (z.B.: AUTOEXEC.BAT). Hierdurch wäre die Freiheit des Anwenders bei der Benennung von Objekten zu stark eingeschränkt.
Eine wesentliche Erleichterung bei der Verwaltung von Objekten ist die grafische Darstellung und Manipulation von Namensräumen. Namen sind hierbei an grafische Symbole gebunden, über die die zugehörigen Objekte manipuliert werden. Daher sollten Namen insbesondere auch dieser Form der Darstellung von Namensräumen Rechnung tragen.
1.1.3 Ortsunabhängigkeit von Namen und Transparenz
Viele verteilte Systeme versuchen, ein integriertes Systemmodell zu realisieren. Dem Benutzer wird dabei die Existenz mehrerer Rechner weitestgehend vorenthalten (single system image). Ihm präsentiert sich das verteilte System wie ein einziges Timesharing-System.
Ein Maß für die Integriertheit eines verteilten Systems ist der realisierte Grad an Transparenz[AL1]. Namen sind bei der Realisierung von Transparenz ein bedeutender Faktor und haben den gestellten Transparenzanforderungen Rechnung zu tragen. Transparenz kann auf unterschiedlichen Ebenen gegeben sein. Am leichtesten ist die Verteiltheit vor dem Benutzer zu verbergen. Weitaus schwieriger hingegen gestaltet sich die Realisierung von Transparenz auf einer niedrigeren Stufe, in der Art, daß das System transparent gegenüber Programmen erscheint, wie dies z.B. durch DSM-Systeme [Carter, 95] versucht wird.
Das ANSA Reference Manual [ANSA, 89] und das Reference Model for Open Distributed Processing der International Standards Organisation [ISO, 92] identifizieren sieben Formen von Transparenz. Die einzelnen Transparenzformen sind zusammen mit den verbundenen Anforderungen an die Namensverwaltung in Tabelle 1.2 aufgeführt.
|
Transparenzform |
Anforderungen
an die Namensverwaltung |
|
Ortstransparenz |
Objekte
werden überall gleich benannt und Namen sind unabhängig vom Aufenthaltsort
eines Objekts. |
|
Zugriffstransparenz |
Der
Zugriff über den Namen muß gleich ablaufen, unabhängig davon, ob das Objekt
lokal oder entfernt gespeichert wird. |
|
Migrationstransparenz |
Objekte
können migrieren, ohne daß Namen geändert werden müssen und der Kontakt zu
einem Objekt verlorengeht. |
|
Replikationstransparenz |
Dem
Anwender muß beim Zugriff über Namen die Existenz verschiedener Replikate
des Objekts verborgen bleiben. |
|
Nebenläufigkeitstransparenz |
Mehrere
Benutzer müssen gleichzeitig über Namen konfliktfrei auf dieselben Objekte
zugreifen können. |
|
Fehlertransparenz |
Bei
Ausfall eines benannten Objekts sollte über den Namen transparent auf eine
Kopie des Objekts zugegriffen werden. |
|
Skalierungstransparenz |
Wachstum
und Rekonfiguration der Namensverwaltung sollten keine merklichen
Auswirkungen auf den Anwender haben. |
Tabelle 1.2: Transparenzformen und ihre Anforderungen an die Namensverwaltung
Die beiden grundlegenden Transparenzformen sind die Orts- und die Zugriffstransparenz. Sie werden oftmals zusammenfassend als Netzwerktransparenz bezeichnet. Weitere Arten wie Leistungs-, Parallelisierungs-, Data-, Execution-, Naming- und Control-Transparenz treten in der Literatur auf, sind jedoch auf die obigen sieben Arten zurückzuführen [Tanenbaum, 92] [Coulouris, 94].
Transparenz durch Namen ist jedoch nur bei einer ortsunabhängigen Benennung von Objekten gewährleistet. Um die gestellten Transparenzanforderungen zu erfüllen, sollten sowohl die Namen globaler als auch lokaler Objekte durch dieselben Mechanismen verwaltet werden und einen einheitlichen logischen Namensraum bilden, unabhängig von der physikalischen oder organisatorischen Struktur des Netzwerks. Außerdem sollte das Binden von Namen an Objekte dynamisch (zur Laufzeit, late binding) erfolgen, um Änderungen der Bindung von Namen an Objekte für den Anwender transparent vornehmen zu können.
1.1.4 Individuelle Anpassungsfähigkeit
Um die Namensgebung an individuelle Erfordernisse anpassen zu können, sollte der Erzeuger eines Objekts bestimmen können, wie es adäquat benannt wird. Dabei besteht das Problem, Objekte so zu benennen, daß auch andere Personen, außer dem Erzeuger, diese anhand von Namen identifizieren können.
Da es jedoch kaum gelingen wird, Namen für Objekte so zu vergeben, daß sie den Wünschen aller Anwender gerecht werden, sollte die Namensverwaltung die Vergabe globaler äquivalenter Namen (Synonyme) zu bestehenden Namen zulassen. Innerhalb des aktuellen Arbeitsbereichs sollte ein Anwender Kurznamen (Aliases) für globale Namen definieren können. Durch das Einrichten von Kontexten (Suchpfaden, Working-Directories und lokalen Verzeichnissen) sollte der Gültigkeitsbereich der Kurznamen festgelegt werden können.
Nicht jeder Anwender sollte denselben globalen Namensraum sehen. Die Vielfalt der vorhandenen Informationen erfordert es, dem Anwender die Möglichkeit zu geben, sich mit Hilfe von Synonymen aus dem globalen einen individuellen Namensraum aufzubauen, der seine persönliche Sicht auf alle relevanten Objekte darstellt.
1.1.5 Flexibilität der Namensanfragen
Ein Objekt, das der Benutzer benannt oder zuvor gesehen hat, ist oftmals leichter anhand des Namens zu identifizieren als durch eine Menge von Attributen, die es beschreiben. Das gleiche gilt für Objekte, die der Benutzer noch nicht gesehen hat, sofern die Informationen geeignet organisiert wurden. Stammen Namen, die im selben Verzeichnis verwendet werden, aus völlig unterschiedlichen Bereichen, so kann der Name eines Objekts genau die entscheidende Eigenschaft erfassen, die es von anderen Objekten unterscheidet.
Obwohl Namen oft bedeutungsvoll sind, können sie das eventuell nur für bestimmte Benutzer sein. Viele Objekte können daher nur durch Eigenschaften identifiziert werden, die durch Namen schwer zu fassen sind. Somit ist es notwendig, nicht nur eine Objektauswahl anhand von Namen treffen zu können, sondern auch anhand einer Beschreibung des Objekts durch Attribute. Eine flexible Möglichkeit zur Beschreibung von Objekteigenschaften durch Namen sowohl bei der Registrierung als auch bei der Namensauflösung ist daher unverzichtbar.
Häufig liegen über gesuchte Objekte nur unvollständige Informationen vor. Um die gewünschten Objekte dennoch zu identifizieren, müssen Namensverwaltungen generische Anfragen unterstützen. Dabei können generische Namen nicht nur einzelne Objekte, sondern ganze Gruppen von Objekten identifizieren. In globalen Namensverwaltungen stellen generische Anfragen ein erhebliches Problem dar, da der Suchraum nicht a priori eingeschränkt werden kann und die Suche somit global zu propagieren ist.
1.1.6 Effizienz der Namensoperationen
Um eine hohe Effizienz der Namensverwaltung zu erreichen, sind einerseits kurze Zugriffszeiten auf Namenseinträge und andererseits ein geringer Verbrauch von Systemressourcen (Speicherbedarf, Rechenzeit, Netzwerkbandbreite) für die Verwaltung von Namen gefordert.
Die Zugriffszeit auf verteilte Objekte ist u.a. durch den Zugriff über Namen bestimmt. Die Anforderungen an die Zugriffszeit sind um so höher, je kurzlebiger die referenzierten Objekte sind. Je häufiger ein Objekt kontaktiert wird, desto effektiver muß die Abbildung des Namens auf den zugehörigen Objekt-Bezeichner sein. Bei regulärer Funktion (Normalfall) der Namensverwaltung sollten nur wenige Resolutionsschritte zur Auflösung eines Namens erforderlich und somit kurze Antwortzeiten garantiert sein. Verzögerungen sind nur bei Ausfall einzelner Namensverwalter zu akzeptieren.
Die Quantität benannter Objekte in verteilten Systemen zwingt eine globale Namensverwaltung zum ökonomischen Haushalten mit Systemressourcen. Namenseinträge sollten daher möglichst wenig Primär- und Sekundärspeicher belegen und die Bearbeitung von Namensoperationen sollte die CPU nicht unnötig belasten. Zur Reduzierung der erforderlichen Bandbreite und zur Minimierung der Netzwerklast insbesondere im Weitverkehrsbereich sollten die zur Namensverwaltung notwendigen Verwaltungsnachrichten verringert und Netzwerk und Rechner belastende Broadcast-Nachrichten weitgehend vermieden werden.
1.1.7 Skalierbarkeit der Namensverwaltung
Mit der zunehmenden Vernetzung aller Bereiche steigt die Anzahl der Anwender von Netzwerkdiensten und damit verbunden global auch die Anzahl benannter Objekte, die in die Namensverwaltung einzubeziehen sind. Gleichzeitig erhöht sich zunehmend die Diversität der zu benennenden Objekte. Bowman und Schwarz [Bowman, 94] identifizieren drei Formen des Wachstums von Netzwerkressourcen, die die Namensverwaltung betreffen (vgl. Tabelle 1.3).
|
Skalierungsdimension |
konzeptuelle Ebene |
Probleme |
Forschungsrichtung |
|
Datenmenge |
Informationsschnittstelle |
Informationsüberlastung |
Themenspezialisierung skalierbare Indizierung
nach Inhalten |
|
Anzahl der Anwender |
Informationsverteilung |
Ungenügende Replikation manuelle Verteilung Topologie |
massive Replikation Zugriffsmessungen Objekt-Caching |
|
Datendiversität |
Informationssammlung |
Datenextraktion schlechte Qualität der
Daten |
Operationsabbildungen Datenabbildungen |
Tabelle 1.3: Dimensionen der Skalierung und damit verbundene Probleme
Proportional zur Anzahl benannter Objekte steigt beständig die Zahl global zu verwaltender Namen (vgl. hierzu auch Abbildung 1.1). Der Zuwachs bei den Anwendern hat eine steigende Belastung der Namensverwaltung durch Anfragen zur Folge. Die zunehmende Diversität der Objekte verlangt eine flexible Möglichkeit zur Beschreibung von Objekten durch Namen.
Globale Namensverwaltungen müssen ein gesichertes Wachstum des Namensraums, der Anwenderbasis und der Datendiversität gewährleisten, d.h. die verwendeten Konzepte und Mechanismen müssen skalieren. Unabdingbar für die Skalierbarkeit ist eine gleichmäßige Verteilung der Last in Form des Speicherbedarfs, der Rechenlast und der Netzwerklast durch Verwaltungsnachrichten. Voraussetzung hierfür ist, daß lokale Veränderungen des Namensraums isoliert behandelt werden und keine globalen Operationen zur Folge haben.
1.1.8 Selbständige Konfigurierung und Administration
Für die Akzeptanz eines System seitens des Benutzers ist die Einfachheit in der Anwendung und die weitgehende Wartungsfreiheit von ausschlaggebender Bedeutung. Der Benutzer sollte sich daher nicht mit den Details der Konfigurierung der Namensverwaltung auseinandersetzen müssen, etwa indem er die Auswahl eines Namensverwalters treffen muß. Dies hat durch die Namensverwaltung selbständig zu geschehen.
Um den Administrationsaufwand zu minimieren und die Namensverwaltung ständig an die Gegebenheiten der Netzwerkinfrastruktur anzupassen, ist es notwendig, daß sich das Netz aus Namensverwaltern selbständig konfiguriert. Dabei sollten die Mechanismen zur Namensverwaltung unabhängig von der Topologie und der Heterogenität des Netzwerks sein.
Die Bereitstellung der Navigationsinformation zur Lokalisierung eines Namenseintrags im Verwalternetz hat selbständig und ohne Administration zu geschehen. Dies ist insbesondere notwendig, um mit der Mobilität und temporären Existenz (Dynamik) von Objekten Schritt halten zu können. Die Relozierung und Migration von Objekten erfordert die selbständige Adaption der Namenseinträge und Navigationsinformation in den Namensverwaltern durch dynamische Mechanismen zur Verwaltung von Namen.
1.1.9 Langlebigkeit der Namensverwaltung
Eng verbunden mit der Existenz eines Objekts ist auch die des zugehörigen Namens. Objekte können jedoch eine sehr unterschiedliche Lebensdauer aufweisen. Eine globale Namensverwaltung hat daher Namen mit sehr differenzierten Lebenszeiten zu verwalten, so daß ihr Betrieb auf Langlebigkeit auszurichten ist.
Während der Lebensdauer der Namensverwaltung ist der Namensraum sehr vielen Änderungen unterworfen. Namen für Objekte werden registriert und wieder gelöscht oder ändern ihre Lokation. Ebenso wird die Basis der Namensverwalter gelegentlich rekonfiguriert, beispielsweise dann, wenn neue Rechner hinzukommen oder veraltete Rechner außer Dienst gestellt werden. Eine einfache Möglichkeit zur Aktualisierung und Rekonfiguration des Namensraums und des Verwalternetzes ist daher unabdingbar.
1.1.10 Hohe Verfügbarkeit und Fehlertoleranz
Eine der wesentlichen Anforderungen an Namensverwaltungen ist eine hohe Verfügbarkeit. Um die Zugriffszeit auch bei zunehmender Ausdehnung des Namensraums zu minimieren sowie Ausfallsicherheit und Fehlertoleranz zu erreichen, müssen globale Namensverwaltungen in der Lage sein,
· mehrere Replikationen desselben Namenseintrags redundant zu verwalten.
· die Replikation benannter Objekte zu berücksichtigen, sofern dies nicht bereits durch den Objektverwalter transparent gehandhabt wird.
· die Ausfallsicherheit der Namensverwaltung durch funktionelle und strukturelle Redundanz zu erhöhen, wobei zumindest der lesende Zugriff auf Namenseinträge zu gewährleisten ist.
· die Isolation fehlerhafter Namenseinträge oder Namensverwalter zu gewährleisten.
· die Konsistenz replizierter Einträge auch nach einer zeitweiligen Netzwerkpartitionierung zu garantieren.
· Namensoperationen bei gleichzeitigem Zugriff auf Namenseinträge zu synchronisieren.
Der Zugriff auf benannte Objekte über Namen sollte immer dann möglich sein, wenn das Objekt selbst verfügbar ist. Der Ausfall eines Namensverwalters darf nicht zur Folge haben, daß ein aktives Objekt über den Namen unzugänglich wird.
Um die aufgezeigten Anforderungen zu erfüllen, sind beim Entwurf einer globalen Namensverwaltung vor allem folgende Fragen zu klären:
· Wie ist die Struktur von Namen zu wählen?
· Wie wird die Abbildung von Namen auf Bezeichner organisiert?
· Wie werden die Namensverwalter im Netzwerk verteilt und konfiguriert?
· Wie werden Namenseinträge auf die einzelnen Namensverwalter verteilt?
Bevor Antworten auf diese Fragen gegeben und Konzepte zur Realisierung der angeführten Anforderungen aufgezeigt werden, sollen in den nächsten Abschnitten die Aufgaben globaler Namensverwaltungen gegenüber anderen Systemdiensten abgegrenzt und die Schwächen existierender Namensverwaltungen in Bezug auf diese Anforderungen identifiziert werden.
Globale Namensverwaltungen müssen den Anforderungen an Skalierbarkeit, Effizienz, Transparenz und Universalität gleichermaßen gerecht werden.
1.2 Abgrenzung zu anderen Systemdiensten
Die globale Verwaltung von Namen tangiert vor allem zwei Bereiche der Informatik, die Kommunikations- und die Datenbanktechnik. Die folgenden Abschnitte sollen Berührungspunkte und Divergenzen aufzeigen und eine Abgrenzung globaler Namensverwaltungen zu diesen angrenzenden Forschungsgebieten vornehmen.
1.2.1 Abgrenzung der Namensverwaltung zur Datenbanktechnik
Globale Namensverwaltungen verkörpern eine spezielle Ausprägung verteilter Datenbanken. Der wesentliche Unterschied ist die Spezialisierung der Namensverwaltung auf die Bereitstellung von Informationen über Informationen (Metainformationen).
Im Gegensatz zu verteilten Datenbanken ist bei Anfragen an Namensverwaltungen die Verteilung der Informationen nicht a priori bekannt. Die Lokation der gewünschten Information wird erst im Laufe der Anfrage ermittelt. Hierzu ist in verteilten Namensverwaltungen zusätzlich Navigationsinformation bereitzustellen, wobei die Verteilung der Informationen sich an organisatorischen oder physikalischen Strukturen orientiert. Die horizontale und vertikale Partitionierung verteilter Datenbanken hingegen resultiert aus den zu erwartenden Zugriffsmustern der Datenbankanwendungen und wird zum Zeitpunkt der Einrichtung der Datenbank festgelegt. Verteilte Datenbanken sind allgemein einsetzbar und setzen keine typischen Anfragemuster voraus, wie diese bei Namensverwaltungen auftreten.
|
|
Verteilte
Datenbank |
Globale
Namensverwaltung |
|
Konsistenz
der Daten |
strikt |
schwach |
|
Art
der Partitionierung |
horizontal und vertikal |
organisatorisch, physikalisch |
|
Zugriffsmuster |
beliebig |
vordefiniert, beschränkt |
|
Einsatzgebiet |
Modellierung des Objekts |
Beschreibung des Objekts |
|
Art
der Daten |
Information |
Metainformation |
|
Struktur
der Daten |
vordefiniert |
vordefiniert bis flexibel |
Tabelle 1.4: Gegenüberstellung der Eigenschaften verteilter Namensverwaltungen und Datenbanken
Wie Tabelle 1.4 verdeutlicht, existieren signifikante Unterschiede zwischen Namensverwaltungen und Datenbanken. Der primäre Unterschied besteht darin, daß der Zugriff auf Objekte über Namen sehr viel restriktiver ist als der über Schlüssel bei Datenbanken. Der Zugriff über Namen ist vergleichbar mit dem Zugriff über Indizes auf Datensätze in verteilten Datenbanken. Indizes in Datenbanken entsprechen der Navigationsinformationen zur Lokalisierung von Namenseinträgen in Namensverwaltungen.
Namensverwaltungen liefern auf Anfragen an Namen gebundene Objekt-Identifikationen, die dem Zugriff auf die benannten Objekte dienen. Namen in hierarchischen Namensverwaltungen besitzen eine vordefinierte syntaktische Struktur, während attributierte Namensverwaltungen sehr viel flexiblere Objektbeschreibungen akzeptieren. Der Anwender besitzt hier die Freiheit, der Namensverwaltung für jedes Objekt eine individuelle Objektbeschreibung zu übergeben. Die Anzahl und Art der Attribute muß nicht wie bei Datenbanken a priori in einem Schema fixiert werden. Eine vergleichbare Flexibilität der Objektdefinition ist allenfalls in objektorientierten Datenbanken anzutreffen.
Namensverwaltungen und verteilte Datenbanken setzen Replikation als Mittel zur Steigerung der Verfügbarkeit ein [Beuter, 96]. Als besondere Problematik erweist sich dabei die Aktualisierung replizierter Einträge. Während verteilte Datenbanken meist die strikte Konsistenz replizierter Informationen fordern, genügen in Namensverwaltungen schwächere Konsistenzbedingungen, falls die Gültigkeit des Namenseintrags beim Objektzugriff geprüft werden kann.
Namensverwaltungen finden auch Anwendung in verteilten Datenbanksystemen selbst. So hat Lindsay den Katalogmanager zur Schemaverwaltung in der verteilten Datenbank R* erstmals als eigenständigen Dienst in verteilten Datenbanksystemen identifiziert [Lindsay, 81].
1.2.2 Abgrenzung der Namensverwaltung zu Kommunikationsdiensten
Ein weithin akzeptiertes Modell zur Beurteilung und Kategorisierung von Kommunikationsdiensten ist das ISO/OSI-Schichtenmodell [ISO, 84], [CCITT, 88a] der International Standards Organisation. Anhand dieses Modells soll eine Aufgabentrennung zwischen Kommunikationsdiensten und der globalen Namensverwaltung vollzogen werden. Anschließend wird die Bedeutung von Namen in TCP/IP-Protokollen [Comer, 88] diskutiert.
1.2.2.1 Namen im ISO/OSI-Schichtenmodell
Im Sinne des ISO/OSI-Schichtenmodells wird ein Dienst einer bestimmten Schicht durch Instanzen dieser Schicht realisiert. Jede Instanz innerhalb einer Schicht N ist eindeutig durch einen N-Instanz-Namen identifiziert. Eine N-Instanz stützt sich auf Dienste der Schicht N-1, indem sie über einen N-1-Dienstzugangspunkt (SAP = Service Access Point) auf eine Instanz der Schicht N-1 zugreift. Ein SAP wird durch eine Dienstzugangspunktadresse identifiziert. Nach [Hauzeur, 86] ist eine N-Dienstzugangspunktadresse einer N+1-Instanz der Name des N-Dienstzugangspunkts, an den sie gebunden ist. Allerdings kann eine N-1-Instanz mehrere N-1-Dienstzugangspunkte bedienen. In jedem Fall wird aber durch eine N-1-Dienstzugangspunktadresse genau eine N-Instanz und eine N-1-Instanz verbunden. Die Adressen selbst sind strukturierte Ziffernfolgen, die wiederum in zahlreiche Formatkategorien eingeteilt werden [Patel, 90].
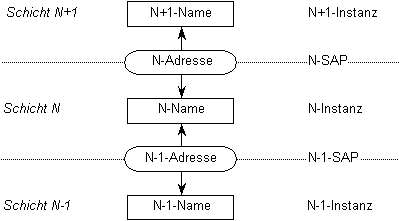
Abbildung 1.2: Adreßkomposition im ISO/OSI-Schichtenmodell
Nach dem soeben aufgezeigten Modell würde die Kommunikation zwischen zwei Prozessen der Anwendungsschicht wie folgt ablaufen [Hauzeur, 86]:
Der Name eines Kommunikationspartners innerhalb der Anwendung wird durch eine Instanz der Anwendungsschicht (bezeichnet mit Schicht N) auf eine N-1-Adresse abgebildet. Eine Instanz der Schicht N-1 ermittelt aus dieser Zieladresse dann eine sogenannte N-1-Route. Diese umfaßt eine Liste von N-1-Namen und stellt einen Pfad zum Zielknoten über N-1-Instanzen dar. Jeder der Namen einer solchen N-1-Route wird dann wieder auf N-2-Adressen und weiter auf N-2-Routen abgebildet, usw. Dieser rekursive Vorgang setzt sich bis zur untersten Schicht fort. Schrittweise entsteht hierdurch ein Baum von Namen und Adressen, dessen Wurzel der Anwendungsname des Kommunikationspartners und dessen Blätter physikalische Adressen sind.
Die Anwendung dieses rekursiven Verfahrens wäre jedoch sehr aufwendig, so daß in der Praxis im ISO/OSI-Modell nur auf der Anwendungsschicht Namen verwendet werden. Auf den anderen Schichten werden direkt Adressen ineinander überführt. Das ist aber auch nur auf den Schichten 2–4 explizit notwendig, auf den anderen Schichten können die Adressen unverändert weitergegeben werden. Ein Anwendungsname kann bereits in der Anwendungsschicht oder aber in der Darstellungs- oder Sitzungsschicht auf eine Transportadresse abgebildet werden (vgl. Abbildung 1.3). Die Transportschicht bildet diese dann direkt auf eine Netzwerkadresse ab. Die Netzwerkschicht ermittelt hieraus eine Route über gekoppelte Router. Die daraus resultierenden Rechneradressen der Sicherungsschicht können dann direkt auf physikalische Adressen abgebildet werden.
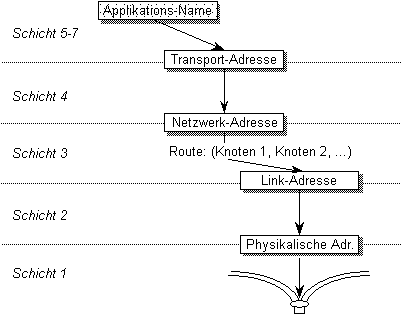
Abbildung 1.3: Abbildung von Namen auf Adressen der ISO/OSI-Schichten
Die Namensverwaltung im ISO/OSI-Modell beschränkt sich somit auf die Umsetzung symbolischer Namen der Anwendungsschicht auf routing-fähige Adressen untergeordneter Schichten. Die auf der Anwendungsschicht des ISO/OSI-Schichtenmodells verwendeten Namen sind über einem hierarchischen Namensraum definiert und können zusätzlich attributiert sein [Patel, 90]. Sie werden durch den OSI-Directory Service [CCITT/ISO, 88] verwaltet, der von der ISO und der CCITT gemeinschaftlich in den Normen ISO-9594 bzw. CCITT X.500 standardisiert wurde.
1.2.2.2 Namen in TCP/IP-Protokollen
Ein Großteil des weltweiten Datenaufkommens[AL2] wird über das Internet mit Hilfe des TCP/IP-Protokolls [Comer, 88] übertragen. Zur Identifikation physikalischer Rechner im Internet werden dabei numerische IP-Adressen mit einer Länge von 4 Bytes verwendet, also beispielsweise von der Form 134.60.77.21. Diese Adressen spiegeln die physikalische Struktur des Internets mit hierarchisch strukturierten Teilnetzen wider. Die Bits innerhalb der Adressen können bedarfsgerecht auf die globale Netzadresse einer Organisation einerseits und auf Teilnetz- und Rechneradressen innerhalb einer Organisation andererseits aufgeteilt werden. IP-Adressen sind Netzwerkadressen und stellen routing-fähige Identifikationen für Rechner dar. Sie bezeichnen selbst jedoch noch keine physikalische Adresse. Die Zuordnung von IP-Adressen zu physikalischen Adressen (z.B. Ethernet-Adressen) erfolgt im Subnetz durch lokale Vereinbarungen. Die Abbildung von IP-Adressen auf physikalische Adressen übernimmt ein spezielles Address Resolution Protocol (ARP).
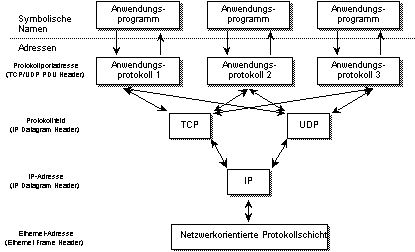
Abbildung 1.4: Namen und Adressen in TCP/IP-Protokollen
Anwendungsprogramme identifizieren Kommunikationspartner im Internet durch hierarchisch strukturierte Namen. Die Namensverwaltung im Internet für TCP/IP und UDP übernimmt das Domain Name System (DNS) [Mockapetris, 83]. DNS beschränkt sich auf die Abbildung symbolischer hierarchischer Namen auf IP-Adressen. Die weitere Weglenkung von IP-Adressen und die Abbildung auf physikalische Adressen bleibt Aufgabe des Kommunikationssystems (IP und ARP). Die für die Adressierung eines Anwenderprotokolls notwendige Protokollportadresse und das Protokollfeld wird durch die Art des Dienstes bestimmt und nicht durch die Namensverwaltung.
Die Adressierung der TCP/IP-Protokolle wurde für stationäre Rechner konzipiert. Mobilitätsaspekte fanden dabei keine Berücksichtigung. Die IP-Adressierung ist daher nicht für hochgradig mobile Rechner geeignet [Katz, 94]. IP-Adressen zur Weglenkung von Paketen durch das Internet sind ortsgebunden. Sobald ein Rechner oder Dienst von einem Netzwerkbereich in einen anderen migriert, muß seine IP-Adresse angepaßt werden, damit er weiterhin erreichbar bleibt. Auch wenn die Lokationsänderung eines Objekts im Internet nicht notwendigerweise mit einer Änderung des Domain Namens verbunden ist, so erfordert die Migration in jedem Fall eine Anpassung der IP-Adresse.
Diesen Mangel an Migrationstransparenz versuchen verschiedene neuere IP-Protokollspezifikationen, wie Mobile IP [Joannidas, 91], VIP [Teraoka, 93], IPng [Simpson, 94a] und IPv6 [Simpson, 94b] zu beheben. In diesen Protokollen wird eine zusätzliche Indirektionsstufe eingeführt, um Pakete an die korrekte temporäre Adresse weiterzuleiten. Durch die Einführung einer Abbildung zwischen der statisch zugeordneten und der dynamisch vergebenen aktuellen IP-Adresse wird die Forderung nach Migrationstransparenz erfüllt.
Jeder mobile Host hat eine eindeutige Heimatadresse. Sobald der mobile Host im Netzwerk migriert, informiert das Kontrollprotokoll den Router, der die Heimatadresse des Knotens verwaltet, über die aktuelle Adresse. Pakete, die an die Heimatadresse adressiert sind, leitet der Router automatisch an die aktuelle Adresse weiter. Dieses Schema ist dem Roaming-Verfahren in zellulären Mobilfunknetzen (z.B. GSM) se
hr ähnlich. Neuere Ansätze basieren auf Techniken, die Forwarding-Informationen in Netzwerk-Routern vorhalten, so daß der Forwarding-Pfad nur einmal pro Sender eingerichtet werden muß. Diese Methoden ermöglichen es, Pakete auf direktem Weg zum mobilen Knoten zu leiten [Perkins, 92] [Bhagwat, 93].
Namensverwaltungen stellen eine spezielle Ausprägung verteilter Datenbanken dar, die zu Namen von Objekten Informationen bereitstellen, anhand derer Kommunikationsprotokolle zu benannten Objekten in Verbindung treten können.
1.3 Schwächen existierender Namensverwaltungen
Nachdem in Abschnitt 1.1 die Anforderungen an globale Namensverwaltungen identifiziert wurden und im vorangegangenen Abschnitt eine Abgrenzung zur Netzwerk- und Datenbanktechnik getroffen wurde, soll nun aufgezeigt werden, inwiefern die in Anhang B vorgestellten Namensverwaltungen und Verzeichnissysteme die gestellten Anforderungen erfüllen können.
1.3.1 Administratives Herstellen der Eindeutigkeit
Eine wichtige Anforderung an Namen ist die Eindeutigkeit innerhalb ihres Gültigkeitsbereichs. Lokale Namensverwaltungen erlauben i.d.R. eine Vergabe von Namen durch den Anwender. Bevor ein benutzerdefinierter Name registriert wird, überprüft die Namensverwaltung seine Eindeutigkeit. Bei der Registrierung eines Namens beispielsweise im NBP [Apple, 90] wird zunächst mit Broadcast-Nachrichten im Netzwerk nach dem zu registrierenden Namen gesucht, um seine Eindeutigkeit zu prüfen. Die Verwendung von Broadcast-Nachrichten setzt der Skalierbarkeit dieser Methode jedoch enge Grenzen. WINS [Microsoft, 96] verwaltet alle Namen eines Bereichs in einem zentralen WINS-Server, so daß die Eindeutigkeit von Namen bei der Registrierung leicht überprüft werden kann.
In verteilten Dateisystemen (z.B. Coda [Satyana., 87]) wird die Freiheit zur Vergabe von Namen durch die Vorgabe eines aktuellen Kontextes, in dem sich der neue Name befindet, eingeschränkt. Die Eindeutigkeit des Kontextnamens ist bereits administrativ gewährleistet, so daß bei der Registrierung eines neuen Namens nur die Einträge innerhalb dieses Kontextes auf Eindeutigkeit geprüft werden müssen.
In statischen Konfigurationsverwaltungen wie NIS [Pickens, 79] und globalen Namensverwaltungen wie DNS [Mockapetris, 88] und X.500 [CCITT/ISO, 88] sind keine Verfahren vorhanden, um die Eindeutigkeit von Namen zu prüfen. Sie muß durch administrative Maßnahmen sichergestellt werden. Daher erlauben diese Systeme auch kein Registrieren globaler Namen durch den Anwender.
1.3.2 Fehlende Unterstützung diverser Objekte
Das Spektrum der in verteilten Systemen zu benennenden Objekte ist sehr breit. Die Objekte zeichnen sich durch eine hohe Diversität in ihrer Struktur und ihren Eigenschaften aus, die in unterschiedlichen Objektbeschreibungen resultiert. Wie in Anhang B gezeigt wird, wurden systeminterne Namensverwaltungen für spezielle Objekte entworfen (Dateien, Geräte und Dienste etc.) und sind daher kaum geeignet, Informationen über beliebige Objekte zu verwalten. Während Konfigurationsverwaltungen (z.B. WINS [Microsoft, 96] und NBP [Apple, 90]) Namen für Rechner, Netzwerke und Dienste bereitstellen, beschränken sich verteilte Dateisysteme (Coda [Satyana., 87], NFS [SUN, 89]) auf die Verwaltung von Namen für Objekte, die durch die Dateiabstraktion zu fassen sind.
Globale Namensverwaltungen wiederum erfassen nur Namen für ein sehr enges Spektrum von Objekten. So verwaltet das Domain Name System (DNS) [Mockapetris, 88] ausschließlich Domain- und Rechnernamen, jedoch keine Namen beliebiger Objekte. X.500 [CCITT/ISO, 88] ermöglicht in seiner derzeitigen Ausprägung des Namensraums ebenfalls nur die Verwaltung von Rechner- und Benutzernamen mit zugehörigen Attributen. Alle Objekte einer Ebene der Verzeichnishierarchie in X.500 gehören derselben Klasse an. Der auf X.500 basierende Novell Directory Service [Novell, 96] erlaubt die Erweiterung des Verzeichnisses um Einträge für beliebige Objekte. Eine Ergänzung der verwalteten Einträge seitens des Anwenders ist jedoch nur theoretisch möglich. Lediglich in Profile [Peterson, 88a] können Objektbeschreibungen für beliebige Objekte durch Attribute definiert werden. Allerdings fehlen in Profile Konzepte zur verteilten Verwaltung attributbasierter Namen.
1.3.3 Fehlende Unterstützung transienter und dynamischer Objekte
Objekte auf Systemebene sind häufig kurzlebig und vielen Änderungen unterworfen. Die Informationen statischer Konfigurationsverwaltungen wie NIS [Pickens, 79] sind daher nur aktuell, wenn sie eine entsprechend intensive Wartung durch den Administrator erfahren. In dynamischen Konfigurationsverwaltungen wie WINS [Microsoft, 96] und NBP [Apple, 90] betreffen Änderungen ausschließlich den lokalen Knoten bzw. Namensverwalter und werden unmittelbar bei der nächsten Anfrage sichtbar. In verteilten Dateisystemen wie Coda [Satyana., 87] und NFS [SUN, 89] wirken sich Änderungen an Namen ebenfalls direkt auf die Verzeichniseinträge aus.
Globale Namensverwaltungen wie DNS [Mockapetris, 88] und Verzeichnisdienste wie z.B. X.500 [CCITT/ISO, 88] wurden für langlebige Objekte, die nur wenige Änderungen erfahren, (z.B. Rechner oder Benutzer) konzipiert. Die Navigationsinformationen und zum Teil auch die Namenseinträge werden daher vom Administrator eingerichtet und gepflegt. Änderungen von Objekteigenschaften, die sich auf den Objektnamen oder die Objektbeschreibung und u.U. auch auf die Navigationsinformation auswirken, müssen in existierenden globalen Namensverwaltungen administrativ vorgenommen werden, so daß die Aktualität der Verzeichnisse in der Regel nicht gegeben ist. Beispielsweise bleiben in manuell administrierten Namensverwaltern häufig Namen auch dann noch erhalten, wenn die zugehörigen Objekte längst nicht mehr existieren (Leichen). Existierende Konzepte für die globale Namensverwaltung eignen sich daher nicht für transiente und dynamische Objekte.
1.3.4 Ortsabhängigkeit und mangelnde Transparenz
In verteilten Systemen ist einerseits die Mobilität von Benutzern und Rechnern, andererseits die Migration von Objekten z.B. aus Gründen der Lastverteilung zu berücksichtigen.
In dynamischen Konfigurationsverwaltungen wie NBP [Apple, 90] und WINS [Microsoft, 96] ist die Lokationsänderung eines Objekts mit dem Löschen und erneuten Registrieren des Namens durch die Anwendung verbunden. In verteilten Dateisystemen wie NFS [SUN, 89] wirken sich aufgrund der Bindung der Verzeichnisstruktur an den physikalischen Speicherort Änderungen der Lokation von Dateien unmittelbar auf Dateinamen aus. Teilbäume hingegen können i.a. durch Anpassung der Mount-Tabellen auf andere Rechner migrieren, ohne daß ihre Namen geändert werden müssen.
Die Struktur der globalen Namensräume in DNS [Mockapetris, 88] und X.500 [CCITT/ISO, 88] reflektiert die physikalische Verteilung der Namenseinträge. Um das Auffinden eines benannten Objekts anhand des Namens auch nach einer Lokationsänderung zu gewährleisten, ist entweder die Änderung des Objektnamens oder aber die Anpassung der Navigations- oder Ortsinformation in den entsprechenden Namensverwaltern erforderlich. Da die in Anhang B vorgestellten globalen Namensverwaltungen nicht in der Lage sind, Namenseinträge dynamisch an neue Gegebenheiten anzupassen, unterstützen sie auch keine mobilen Objekte.
Zur Schaffung globaler Namensräume, die auch lokale Objekte erfassen, werden in verschiedenen Netzwerkanwendungen lokale und globale Namensräume kombiniert. Hierdurch erweitert sich die Quantität und das Spektrum der im Namensraum erfaßten Objekte erheblich. Bei ungenügend realisierter Transparenz machen sich zusammengesetzte Namensräume durch einen syntaktischen Bruch in den Namen bemerkbar (z.B.: hermes.informatik.uni-ulm.de /usr/bin/make). Ein syntaktischer Bruch ist z.B. in URLs [Berners-Lee, 94] (Uniform Resource Locators), wie sie im World-Wide Web (WWW) [Berners-Lee, 92] Verwendung finden, deutlich erkennbar.
Die Änderung der Lokation einer WWW-Seite erfordert im günstigsten Fall lediglich die Änderung der IP-Adresse des WWW-Servers. Sofern keine selbständige Anpassung der Bindung des Namens an die IP-Adresse etwa durch WINS [Microsoft, 96] oder Dynamic DNS [Bound, 94] erfolgt, muß diese im Domain Name Server manuell angepaßt werden. Ändert sich bei der Migration einer WWW-Seite hingegen der Name des WWW-Servers oder der HTML-Datei, so invalidiert dies stets alle Referenzen (URLs) auf diese Seite. Da URLs im WWW in HTML-Dokumenten abgelegt sind, besteht bei Änderung des Namens einer WWW-Seite keine Möglichkeit, diese Referenz entsprechend anzupassen. Man kann ungültige Referenzen als Beweis für die “Lebendigkeit des Internets” akzeptieren, naheliegender ist es jedoch, diese als erheblichen Mangel im Entwurf globaler Informationssysteme zu betrachten. Die tiefere Ursache hierfür liegt in der unzureichenden Integration lokaler und globaler Namensräume und in der Ortsabhängigkeit derartiger globaler Namen.
Um das Update-Problem von URLs zu lösen, wurde an der Universität Graz das zum WWW kompatible Hyper-G [Kappe, 93] System entwickelt. Hyper-G verwaltet globale Referenzen getrennt vom Inhalt einer Seite in einer Datenbank, so daß sie bei Änderungen leicht aktualisiert werden können.
1.3.5 Fehlende individuelle Anpassungsfähigkeit
Die Anpassungsfähigkeit einer Namensverwaltung an die Bedürfnisse des Anwenders wird maßgeblich von der Unterstützung von Synonymen und Alias-Namen bestimmt. Verteilte Dateisysteme, wie NFS [SUN, 89] unterstützen Synonyme in Form von Links, die auf Dateien in anderen Unterbäumen verweisen. Im aktuellen Kontext können ferner Alias-Namen für globale Einträge vergeben werden. In AFS und Coda [Satyana., 87] werden Suchpfade definiert, bezüglich derer Alias-Namen aufgelöst werden. Das Dateisystem Prospero [Neuman, 92a] erlaubt das Anlegen virtueller Verzeichnisse für den Aufbau individueller Sichten für Benutzer. Hierzu stehen Synonyme, Filterfunktionen und objektinterne Startkontexte zur Verfügung.
In Clearinghouse [Oppen, 83] tragen benannte Objekte einen eindeutigen primären Namen sowie optional mehrere Synonyme. GNS [Lampson, 86] stellt dem Anwender eine working root und Alias-Namen zur Verfügung. Das Domain Name System [Mockapetris, 87a] unterstützt Alias-Namen für die Host-Namen innerhalb einer Domain. Die Einrichtung globaler Synonyme ist nur theoretisch denkbar, in der Praxis wären hierzu administrative Änderungen auf allen Ebenen von Namensverwaltern erforderlich. X.500 [CCITT, 89] erlaubt Alias-Namen in lokalen Kontexten an den Blättern des Directory Information Tree (DIT). Globale Synonyme sind in X.500 ähnlich schwer zu realisieren wie in DNS.
Zusammenfassend läßt sich festhalten, daß lokale Namensverwaltungen i.a. effektiv Synonyme und Alias-Namen unterstützen, während in globalen Namensverwaltungen die manuelle Administration der Verzeichniseinträge und Navigationsinformationen das Einrichten globaler Synonyme und individueller Objektbeschreibungen durch den Benutzer verhindert.
1.3.6 Fehlende Unterstützung flexibler Namensanfragen
Eine der primären Annahmen in den in Anhang B vorgestellten globalen Namensverwaltungen und Verzeichnisdiensten ist, daß sich jeder Eintrag an einer bestimmten Stelle in einem hierarchischen Namensraum befindet. Diese Annahme erscheint adäquat, um Einträge zu lesen, deren Position in der Hierarchie bekannt sind. Probleme erwachsen jedoch, wenn Namenseinträge für Objekte im Namensraum ermitteln werden sollen, die bestimmte Eigenschaften erfüllen oder deren Namen nur teilweise bekannt sind. In diesem Fall wird eine globale Suche eingeleitet, wobei die Anfrage in allen Unterbäumen des Startpunkts propagiert wird. Das damit verbundene hohe Nachrichtenaufkommen ist dabei nicht das größte Problem; solche Anfragen belasten das Netzwerk nicht allzusehr. Verhältnismäßig teuer jedoch ist, daß jeder Namensverwalter, der eine Anfrage erhält, diese bearbeiten muß, und zwar auch dann, wenn er überhaupt keine Einträge verwaltet, die die gewünschten Kriterien erfüllen können [Deutsch, 94]. Ein spärlich ausgelegter oder schlanker Namensraum bewirkt dabei, daß der größte Teil von Anfragen global verteilt wird, während ein sehr breit angelegter Namensraum seine eigenen Navigationsprobleme mit sich bringt. Aus diesen Gründen ist in X.500 [CCITT, 89] auf höheren Ebenen des Namensraums die Suche nach Attributen und generischen Namen untersagt und DNS verbietet generische Anfrage grundsätzlich.
Wenn die globale Suche aber nicht möglich ist, dann müssen Informationen existieren, wie der Namensraum beschaffen ist, um die Suche an die passende Stelle leiten zu können. Somit wird die Struktur des Namensraums ausschlaggebend für den Erfolg des Anwenders bei der Suche nach der gewünschten Information. Dies führt zu endlosen Diskussionen, wie der Namensraum beschaffen sein muß, um den Anforderungen einer bestimmten Gruppe von Anwendern zu genügen. Enormes Kopfzerbrechen ist unvermeidlich, jedesmal wenn sich herausstellt, daß die Struktur des Namensraums für den gegenwärtigen Einsatz nicht passend gewählt wurde und umstrukturiert werden muß, wie dies in jüngster Vergangenheit bei X.500 der Fall war. Bisher gibt es noch nicht einmal eine Übereinkunft, wie der X.500-Namensraum für die Einträge des White Pages-Dienstes in Pilotprojekten gestaltet werden soll.
1.3.7 Geringe Effizienz der Namensverwaltung
Die Effizienz von Operationen auf Namensräumen, z.B. beim Zugriff auf Dateien und Dienste, ist ein maßgeblicher Faktor für die Gesamtleistung eines verteilten Systems. Insbesondere die Namensverwaltung für Dateien und kurzlebige Objekte in verteilten Systemen, wie Prozesse und Kommunikationskanäle, muß diesem Aspekt in besonderem Maße Rechnung tragen [Cheriton, 88].
Konfigurationsverwaltungen wie NBP [Apple, 90] und verteilte Dateisysteme wie AFS und Coda [Satyana., 87] realisieren eine sehr effiziente Namensauflösung für Dienstzugangspunkte bzw. Dateien in lokalen Netzwerken. Während NBP zur Effizienzsteigerung lediglich das Vorhalten von Namenseinträgen auf Anwendungsebene unterstützt, ist die Replikation von Verzeichniseinträgen in verteilten Dateisystemen wie AFS und Coda ein zentrales Konzept.
Viele der in der Vergangenheit beschriebenen globalen Namensverwaltungen [Birell, 82] [Birell, 84] [Lampson, 86] zielen auf die Verwaltung von Namen selten adressierter und sich wenig ändernder Objekte in großen Netzwerken (Hostrechner, Mailboxen u.ä.) ab, wobei Effizienzaspekte von untergeordneter Bedeutung sind. Da die Auflösung globaler Namen jedoch relativ viel Zeit in Anspruch nimmt, unterstützen globale Namensverwaltungen wie DNS [Mockapetris, 87a] sowohl das klientenseitige Vorhalten von Namenseinträgen als auch regionale Caches.
1.3.8 Mangelnde Skalierbarkeit
Mangelnde Skalierbarkeit ist primär eine Schwäche lokaler Namensverwaltungen, die integraler Bestandteil von Systemdiensten sind. In Konfigurationsverwaltungen (vgl. Abschnitt B.1) werden Namen verfügbarer Dienste in zentralen Tabellen gehalten, die über das Netz von verschiedenen Rechnern gelesen werden. Gerade diese zentrale Verwaltungsmethode ist es, die nicht skaliert. Dynamische Methoden der Konfigurationsverwaltung (vgl. NBP [Apple, 90]) verwalten Namen entweder völlig dezentral, wobei Namen ausschließlich lokal auf den Ursprungsknoten registriert und nicht verteilt werden, oder, wie in WINS [Microsoft, 96], zentral in einem Namensverwalter. Für die Namensauflösung in NBP [Apple, 90] wird ein Broadcast-Verfahren eingesetzt, wodurch die Namensverwaltung auf das lokale Netzwerk beschränkt bleibt. In WINS [Microsoft, 96] hingegen ist die Skalierbarkeit durch das Konzept des zentralen WINS-Servers begrenzt.
Zum Einrichten verteilter Dateiverzeichnisse existieren unterschiedliche Methoden. Die besten Skalierungseigenschaften sind dabei den Verfahren zuzuschreiben, die eine zusätzliche Dimension einführen, d.h. einen lokalen und einen globalen Namensraum verbinden. Das Ausweisen einer „super root“ zeigt ebenfalls gute Skalierungseigenschaften, solange zusätzlich Verzeichniseinträge vorgehalten werden. Das Montieren von Verzeichniseinträgen (z.B. in NFS) erfordert in jedem Rechner die Verwaltung von „Mount“-Tabellen, wodurch der Skalierbarkeit enge Grenzen gesetzt sind. Moderne verteilte Dateisysteme, wie AFS und Coda [Satyana., 90a] unterteilen die Verzeichnisstruktur in einen lokalen und einen gemeinsamen Bereich, so daß die Anzahl der zu verwaltenden externen Verweise begrenzt ist. Zudem werden neben Dateien auch Verzeichniseinträge vorgehalten.
Objekte können durch attributierte Namen beschrieben und identifiziert werden. Da sich die Verwaltung attributierter Namen jedoch i.a. auf Broadcast-Verfahren oder zentrale Verwalter stützt, skaliert sie nicht. Um attributierte Namensräume global zu erweitern, werden häufig lokale attributierte Namensräume an den Blättern eines globalen Verzeichnisbaums plaziert (z.B. in Profile). Dadurch wird die globale Suche nach Attributwerten äußerst aufwendig und muß in ihrer Ausdehnung beschränkt bleiben.
Verschiedene globale Namensverwaltungen, wie Clearinghouse [Oppen, 83] und Grapevine [Birell, 82], weisen Beschränkungen in der Anzahl der Hierarchiestufen des Namensraums oder des Verwalternetzes auf und sind daher nicht beliebig skalierbar. Hingegen basieren DNS [Mockapetris, 87a] und X.500 auf dem „super root“-Ansatz zur Schaffung gemeinsamer Namensräume, so daß die Skalierbarkeit bereits durch das Konstruktionsprinzip gewährleistet ist. Diese Systeme weisen eine variable Anzahl von Hierarchieebenen sowohl des Namensraums als auch des Verwalternetzes auf. Die Skalierbarkeit ist somit nicht durch die Struktur des Namensraums oder des Verwalternetzes limitiert. Das Wachstum von DNS wird jedoch durch die restriktive Vergabe von Top Level Domains (z.B. com, de, usw.) durch die zuständige Behörde und die beschränkte Anzahl von sinnvollen Domain Namen in den bestehenden Top Level Domains stark behindert (vgl. Artikel aus der Computerzeitung im Vorwort der Arbeit).
1.3.9 Manuelle Administration globaler Namensverwaltungen
Die Basis der benannten Objekte in verteilten Systemen ist zahlreichen Änderungen unterworfen, so daß die Verwaltung von Namen für diese Objekte unweigerlich ein hohes Maß an Administration erfordert. Der Umfang an manuell zu verrichtender Administrationsarbeit ist jedoch sehr stark abhängig von der jeweiligen Namensverwaltung.
Während die Verwaltung von Konfigurationen in NIS [Pickens, 79] manuell durch einen Administrator in zentralen Tabellen erfolgt, ist das verteilte Names Directory in NBP [Apple, 90] ganz dem Einfluß des Administrators entzogen. Auch WINS [Microsoft, 96] erlaubt dem Klienten selbständig Namen beim zentralen WINS-Server zu registrieren und wieder zu entfernen. In Verbindung mit DHCP [Droms, 93] ermöglicht WINS die dynamische Vergabe und Zuordnung von Adressen zu Namen.
In verteilten Dateisystemen wird die Struktur der Verzeichnisse vom Systemadministrator angelegt. Der Anwender hat lediglich die Freiheit, Einträge in ihm zugänglichen Unterverzeichnissen anzulegen. Entfernte Verweise müssen vom Administrator des Zielrechners erst verfügbar gemacht werden.
Während im lokalen Bereich sehr differenzierte Administrationsarbeit zu leisten ist, besteht in globalen Namensverwaltungen durch die räumliche Trennung der Namensverwalter und die starre Verteilung des Namensraums auf Namensverwalter die administrative Herausforderung vorwiegend in der Bereitstellung der Navigationsinformation in den Namensverwaltern. So sind im Domain Name System [Mockapetris, 87a] neue Rechner beim zuständigen Name Server manuell einzutragen und auch die Domain-Einträge in übergeordneten Name Servern werden von Hand registriert. Beim Klienten ist zu konfigurieren, wo sich der zuständige Name Server im Netzwerk befindet. Diese Schwächen des DNS wurden auch von der Internet Engineering Task Force (IETF) erkannt. So wurde von der IETF eine Erweiterung des DNS, das sog. Dynamic DNS [Bound, 94] vorgeschlagen, das zumindest das automatische Registrieren und Aktualisieren von DNS-Einträgen ermöglicht. Die zur globalen Namensauflösung notwendigen Navigationsinformationen müssen jedoch weiterhin manuell bereitgestellt werden.
Die Einrichtung und Pflege der Directory-Informationen eines X.500 Directory System Agent (DSA) [CCITT, 89] erfordert nicht weniger administrativen Aufwand. Die Navigationsinformation in DSAs wird manuell administriert und ist noch aufwendiger zu warten als die in DNS. Lediglich in der X.500-Implementierung DIR X [SNI, 93a] von Siemens können Verzeichniseinträge in Blättern eines Directory Information Tree (DIT) mit der entsprechenden Zugriffsberechtigung durch Benutzerinteraktionen modifiziert werden. Der auf X.500 basierende Novell Directory Service [Novell, 96] hingegen ermöglicht die zentrale Administration von X.500-Verzeichnissen und bietet einen grafischen Browser, mit dem Verzeichniseinträge mit der Maus manipuliert werden können.
1.3.10 Lebenszeit von Namensverwaltungen
Lokale Namensverwaltungen verwalten i.d.R. Namen für dynamische, feingranulare Objekte mit sehr unterschiedlicher Lebensdauer. Während NBP [Apple, 90] eine vollständig verteilte Namensbasis unterhält, deren Einträge genau solange leben wie die gebundenen Objekte, können Verzeichnisse in verteilten Dateisystemen sowohl temporären Charakter haben als auch auf Dauer angelegt sein. Da die Existenz von Namen in NBP und verteilten Dateisystemen sehr eng mit der Existenz des gebundenen Objekts gekoppelt sind, können deren Verzeichnisse keine veralteten Einträge enthalten. In WINS [Microsoft, 96] registriert bzw. löscht ein Klient seinen Namen beim WINS-Server, sobald er im Netzwerk aktiv bzw. inaktiv wird. Namen, die von WINS verwaltet werden, erhalten bei der Registrierung eine Time to Live (TTL) oder ein Erneuerungsintervall. Da es Aufgabe des Klienten ist, die Namenseinträge zu erneuern, enthält das Verzeichnis keine veralteten und ungültigen Einträge.
Globale Namensverwaltungen wie DNS [Mockapetris, 87a] enthalten Namen für relativ langlebige Objekte. Sie sind für eine lange Lebensdauer konzipiert, in der die Namensbasis wenigen Änderungen unterworfen ist. Das starke Wachstum globaler Netzwerke erfordert jedoch vermehrt eine Anpassung der Namensverwaltung und erhöht den Administrationsbedarf. Da die Lebenszeit globaler Namenseinträge in Namensverwaltern nicht direkt an die Existenz der benannten Objekte gebunden ist und Änderungen stets Administrationsarbeit verlangen, ist die Aktualität globaler Namenseinträge i.a. nicht gewährleistet. Mechanismen, die die Gültigkeit von Namenseinträgen prüfen, sind nicht vorgesehen, weshalb globale Namensverzeichnisse mit der Zeit zunehmend mehr Namen von nicht mehr existenten Objekten enthalten.
1.3.11 Fehlende Ausfallsicherheit und Fehlertoleranz
Die Verfügbarkeit des Namensdienstes ist ein zentrales Kriterium für die Zuverlässigkeit des gesamten verteilten Systems. Dabei ist vor allem der Grad der Integration des Namensdienstes mit anderen Systemdiensten entscheidend.
In vollständig verteilten Namensverwaltungen wie dem NBP [Apple, 90] und in verteilten Dateisystemen ist gewährleistet, daß ein Objekt oder eine Datei immer dann zugreifbar ist, wenn auch der zugehörige Namenseintrag verfügbar ist. Der Ausfall eines Rechners hat das Verschwinden einer Menge von Verzeichnissen und der zugehörigen Objekte zur Folge. Das z.Z. fortschrittlichste verteilte Dateisystem Coda, eine Weiterentwicklung von AFS [Satyana., 87] versucht durch Datei- und Verzeichnisreplikation eine hohe Ausfallsicherheit zu erzielen. Coda bietet durch Voting- und Merge-Protokolle auch Unterstützung zum Abgleich modifizierter Replikationen bei Vorliegen einer Netzwerkpartitionierung. WINS [Microsoft, 96] ist aufgrund der zentralen Organisation besonders anfällig. Zur Steigerung der Ausfallsicherheit wird daher der primäre WINS-Server auf einem sekundären Server repliziert. Zusätzliche Sicherheit bei Ausfall und Initialisierung der hierarchischen Namensverwaltung im System V [Cheriton, 84a] wurde erzielt, indem die Multicast-Eigenschaften über das lokale Netzwerk hinaus in den Bereich globaler Netze ausgedehnt wurden. Bei Ausfall oder Initialisierung von Verbindungsservern kann bei Servern benachbarter Netzwerke nach Namen gesucht werden.
In globalen Namensverwaltungen liegt i.a. eine Trennung der Namensverwaltung vom jeweiligen Dienst vor. Daher kann es durchaus sein, daß Objekte verfügbar sind, jedoch nicht der Name, und umgekehrt. Diese lose Kopplung von Name und Objekt erfordert zusätzliche Maßnahmen zur Erhöhung der Ausfallsicherheit der Namensverwaltung. Globale Namensverwaltungen, wie DNS [Mockapetris, 87a] und auch Grapevine [Birell, 82], erreichen durch die Replikation von Namenseinträgen einen hohen Grad an Fehlertoleranz.
Um die Verfügbarkeit von Namensdaten zu gewährleisten, sieht die DNS-Architektur vor, daß die Namensdaten jeder Zone auf mindestens zwei voneinander unabhängigen Servern zu replizieren sind. Zur Replikationsverwaltung wird ein zeitstempelbasiertes Verfahren mit abgeschwächter Konsistenzgarantie verwendet. Der sekundäre Server prüft periodisch die Aktualität seiner Daten, wobei die Frequenz der Validierung vom Administrator vorgegeben wird. Bei Ausfall eines Name Servers kann der Klient eine Liste von Servern vorgeben, die sukzessive kontaktiert werden sollen.
X.500 [CCITT/ISO, 88] sieht im Standard keine Replikationsmaßnahmen zur Steigerung der Ausfallsicherheit vor. In einzelnen Implementierungen von X.500, wie NDS [Novell, 96] und DIR X [SNI, 93a], wurde allerdings deren Notwendigkeit erkannt und Maßnahmen zur Fehlertoleranz und Replikationsverwaltung getroffen.
1.3.12 Bündelung der Schwächen existierender Namensverwaltungen
Wie in diesem Abschnitt gezeigt wurde, resultieren die Stärken und Schwächen der diskutierten Konzepte in erster Linie aus den unterschiedlichen Zielsetzungen lokaler und globaler Namensverwaltungen. Die bedeutendsten Unterschiede faßt nachfolgende Tabelle zusammen:
|
|
Lokale Namensverwaltungen |
Globale Namensverwaltungen |
|
Granularität
benannter Objekte |
fein –
grob |
grob |
|
Lebensdauer
benannter Objekte |
kurzlebig |
langlebig |
|
Diversität
benannter Objekte |
hoch |
gering |
|
Mobilität
benannter Objekte |
hoch |
gering |
|
Dynamik
der Mechanismen |
hoch |
gering |
|
Skalierbarkeit
der Mechanismen |
gering |
hoch |
Tabelle 1.5: Gegenüberstellung der Eigenschaften lokaler und globaler Namensverwaltungen[AL3]
Tabelle 1.5 bringt zum Ausdruck, daß lokale Namensverwaltungen eine höhere Flexibilität und Dynamik in der Verwaltung von Namen aufweisen, jedoch schlecht skalieren. Globale Namensverwaltungen zeigen ein wesentlich besseres Skalierungsverhalten, besitzen jedoch eine starre Verzeichnisstruktur, die i.d.R. manuell administriert werden muß.
Nachdem die Schwächen existierender Namensverwaltungen identifiziert wurden, werden im nächsten Abschnitt Konzepte zur dynamischen Verwaltung globaler Namensräume vorgestellt, die die positiven Eigenschaften lokaler und globaler Namensverwaltungen vereinen und ihre Nachteile vermeiden. Die Tragfähigkeit dieser Konzepte wurde durch die Implementierung eines Prototyps zur dynamischen globalen Namensverwaltung nachgewiesen.
Die größte Schwäche globaler Namensverwaltungen liegt in der manuellen Administration der Namenseinträge und der zur globalen Namensauflösung erforderlichen Navigationsinformation.
1.4 Konzepte der dynamischen globalen Namensverwaltung
Die in Abschnitt 1.1 aufgestellten Anforderungen an eine globale Namensverwaltung sind nicht trivial zu realisieren. Wie Abschnitt 1.3 zu entnehmen ist, erfüllen bisherige globale Namensverwaltungen die gestellten Anforderungen nur bedingt, weshalb neue Konzepte für die globale Namensverwaltung erforderlich sind.
Im folgenden werden Konzepte für eine dynamische globale Namensverwaltung aufgezeigt, die die gestellten Anforderungen realisieren:
· Selbständige Verwaltung des Namensraums
·
Prüfen der Eindeutigkeit: Die globale Eindeutigkeit von Namen wird
nicht administrativ, sondern durch Prüfen hergestellt.
·
Syntaxgesteuerte Plazierung: Globale Namen werden beim Registrieren
syntaxgesteuert im Namensraum und im Verwalternetz plaziert.
·
Selbständige Kontextbildung: Neu hinzukommende Namen werden, sofern
möglich, selbständig zu übergeordneten Kontexten (logische Gruppierung)
vereint.
·
Automatische Generierung von
Navigationsinformation: Die zum
Auflösen globaler Namen erforderliche Navigationsinformation wird selbständig
in den Namensverwaltern generiert und beim Löschen von Einträgen wieder
entfernt.
· Einheitlicher Namensraum
·
Integration hierarchischer und
attributierter Namen:
Objektbeschreibungen durch attributierte Namen werden von der dynamischen
globalen Namensverwaltung auf globale hierarchische Namensräume abgebildet.
·
Individualisierung durch Synonyme: Synonyme, die sowohl mit globaler als auch
mit lokaler Signifikanz versehen werden können, ermöglichen dem Anwender die
individuelle Gestaltung seines Namensraums.
·
Ortsunabhängigkeit von Namen: Der globale Namensraum enthält logische
Namen, die unabhängig von der physikalischen oder organisatorischen Struktur
des zugrundeliegenden Netzwerks sind.
·
Integration lokaler und globaler
Namensräume: Die geforderte
Transparenz beim Zugriff verteilter Objekte und die Einheitlichkeit der
Mechanismen zur Namensverwaltung wird gewährleistet, indem Namen mit lokaler
und globaler Signifikanz in einem universellen globalen Namensraum verwaltet
werden.
· Selbständige Konfigurierung des Verwalternetzes
· Gleichberechtigte Namensverwalter: Durch die Aufhebung der funktionalen Trennung von Klient und Name Server wird eine durchgängige Namensverwaltung ermöglicht, die lokale Namenseinträge nahtlos in den globalen Namensraum integriert.
·
Selbständige Konfigurierung der
Namensverwalter: Um den Anwender
der Namensverwaltung von administrativen Aufgaben zu befreien und flexibel auf
Systemausfälle reagieren zu können, wird das Verwalternetz automatisch
konfiguriert und adaptiert. Die Konfigurierung des Verwalternetzes
berücksichtigt topologische und funktionale Gegebenheiten der zugrundeliegenden
Kommunikationsinfrastruktur.
·
Unabhängigkeit der Mechanismen von der
Netzwerktopologie: Die
Mechanismen zur Namensverwaltung greifen je nach Netzwerkeigenschaft für den
Anwender transparent auf verschiedene Strategien zur Auflösung und
Registrierung von Namen zurück.
· Attributierte und generische Anfragen
·
Attributierte und generische Anfragen: Individuelle und unspezifische Objektbeschreibungen
werden durch attributierte und generische Anfragen realisiert. Diese werden bei
Nichteindeutigkeit parallel ausgeführt, wobei der Suchraum durch die Angabe
eines Startkontextes und durch Navigation eingeschränkt werden kann.
·
Verwaltung der Ergebnisse von
Namensanfragen als virtueller Namensraum: Die Ergebnisse generischer oder attributierter Anfragen bilden lokal
einen virtuellen Namensraum. Diese Art der Präsentation von
Anfrageergebnissen erleichtert dem Anwender das Auffinden relevanter
Namenseinträge.
·
Objektauswahl durch Auflösung und
Selektion: Attributierte und
generische Anfragen liefern u.U. eine Resultatmenge. Der Anwender muß daher
aus der Resultatmenge eine Auswahl treffen können, um die für ihn relevanten
Einträge weiter einzugrenzen und eine erneute Anfrage sukzessive zu
präzisieren.
· Adaptive Replikation
·
Adaptives Vorhalten: Das mehrstufige Vorhalten von Namenseinträgen
reduziert die Auflösungszeit und den erforderlichen Nachrichtenaufwand und
sichert gleichzeitig die Konsistenz vorgehaltener Namenseinträge.
·
Flexible Anpassung der Lebenszeit: Die TTL (time to live) eines Kontexts wird
auf das Maximum der TTLs der enthaltenen Namenseinträge festgesetzt.
·
Steigerung der Verfügbarkeit durch
Replikation: Namensverwalter
derselben Stufe im Verwalternetz werden automatisch repliziert, um die
Verfügbarkeit der globalen Namensverwaltung zu steigern.
·
Konsistenzerhaltung durch optimistische
Verfahren: Replizierte
Namensverwalter können bei Partitionierung unabhängig voneinander
weiterarbeiten und werden abgeglichen, sobald sie wieder zueinander in
Verbindung stehen.
In diesem Kapitel wurden zunächst die Anforderungen an globale Namensverwaltungen sowie die Vorzüge und Schwächen existierender Namensdienste aufgezeigt. Um deren Schwächen zu vermeiden und die in Abschnitt 1.1 gestellten Anforderungen zu erfüllen, wurden neue Konzepte zur dynamischen globalen Namensverwaltung vorgestellt, die in den nachfolgenden Kapiteln im Detail diskutiert werden. Die Tragfähigkeit und Effizienz dieser Konzepte wurden durch eine Prototypimplementierung unter Beweis gestellt.
Die dynamische globale Namensverwaltung bietet Konzepte für die automatische Konfigurierung des Verwalternetzes und die selbständige Verwaltung eines globalen Namensraums.