In Kapitel 2 wurden verschiedene Strukturen von Namensräumen diskutiert und hierarchische Namensräume als besonders geeignet für die globale Verwaltung von Namen identifiziert. Kapitel 3 diskutierte Organisationsformen der Namensverwaltung und stellte eine Methode zur dynamischen Konfigurierung hierarchischer Verwalternetze in Abhängigkeit von der Netzwerktopologie und den Netzwerkeigenschaften vor. Im Mittelpunkt des folgenden Kapitels steht die globale Auflösung (Resolution) hierarchischer Namen und die adäquate Verteilung eines globalen hierarchischen Namensraums auf ein hierarchisches Verwalternetz.
4.1 Auflösung globaler Namen
Voraussetzung zum Verständnis der Vorgehensweise bei der Plazierung globaler Namen im Verwalternetz ist die Kenntnis existierender Methoden zur Auflösung globaler Namen. Dieser Abschnitt präsentiert daher zunächst einige allgemeine Methoden zur globalen Auflösung von Namen in hierarchischen Verwalternetzen.
Die globale Auflösung von Namen besteht im wesentlichen aus drei Schritten:
1. Dem Lokalisieren des für den Namen zuständigen Namensverwalters im Verwalternetz.
2. Der lokalen Auflösung des entsprechenden Namens innerhalb eines Namensverwalters.
3. Dem Zurückliefern der Ergebnisse der Namensauflösung zum Initiator der Anfrage.
Globale Namen werden innerhalb und zwischen Namensverwaltern aufgelöst. Jeder Auflösungsschritt ist mit einem Kontextwechsel oder dem Übergang in einen anderen Namensraum verbunden. Ein Auflösungsschritt liefert somit einen neuen Namen, einen Kontext in einem (neuen) Namensraum, bezüglich dessen der Name weiter aufgelöst wird, und den Namensverwalter, in dem der Kontext bzw. der Namensraum administriert wird.
4.1.1 Verfahren zur Auflösung globaler Namen
Die Namenseinträge globaler Namen sind im Verwalternetz verteilt und a priori ist nicht bekannt, welcher Namensverwalter den Namenseintrag für einen bestimmten Namen hält. Die Auflösung globaler Namen ist daher stets mit der Lokalisierung der zugehörigen Namenseinträge im Verwalternetz verbunden. Grundsätzlich existieren zur Auflösung globaler Namen zwei unterschiedliche Verfahren, die sich durch die Art der Lokalisierung von Namenseinträgen im Verwalternetz unterscheiden, die strukturorientierte und die strukturunabhängige Auflösung.
Strukturorientierte Methoden zur globalen Auflösung von Namen analysieren sukzessive die Komponenten eines Namens und entscheiden anhand der Semantik der Namensbestandteile und der im jeweiligen Namensverwalter verfügbaren Navigationsinformation, welcher Namensverwalter für die Auflösung des jeweils nächsten Namensteils kontaktiert werden muß. Dieser Vorgang kann auch als Interpretation eines Namens oder als Navigation im Verwalternetz verstanden werden. Der Vorgang der Lokalisierung von Namensverwaltern wechselt sich mit der Auflösung des Namens ab, bis der Name aufgelöst und der für den zugehörigen Namenseintrag zuständige Namensverwalter lokalisiert ist.
Strukturunabhängige Verfahren zur globalen Auflösung von Namen trennen den Vorgang der Lokalisierung des zuständigen Namensverwalters und die eigentliche Auflösung des Namens zum Objekt-Bezeichner. Im ersten Schritt wird unabhängig von der Struktur des aufzulösenden Namens der für die Verwaltung des zugehörigen Namenseintrags zuständige Namensverwalter im Verwalternetz lokalisiert. Anschließend findet dort lokal die Auflösung des Namens zum Objekt-Bezeichner statt.
Erstrecken sich Namensauflösungen über verschiedene Namensräume, so können auf jeder Stufe der Auflösung unterschiedliche Methoden zur Lokalisierung der für einen Namensteil zuständigen Namensverwalter Verwendung finden. Exemplarisch sei hier die zweistufige Auflösung von Domain Namen auf Ethernet-Adressen in Erinnerung gebracht.
4.1.1.1 Strukturunabhängige Namensauflösung
Die Lokalisierungsverfahren der strukturunabhängigen Namensauflösung, auch als streuende Lokalisierungsverfahren bekannt, leiten Namensanfragen an alle im Verwalternetz in Frage kommenden Namensverwalter. Dabei werden Namensanfragen dupliziert, was jedoch mit der Semantik globaler Namensoperationen durchaus verträglich ist, sofern die Namenseinträge selbst als Unikate vorliegen. Nicht unmittelbar einsichtig ist die Verträglichkeit, wenn Namenseinträge mehrfach gehalten werden, da bei Vorliegen gleichberechtigter Kopien Änderungsoperationen dann zu sich selbst in Konkurrenz geraten können. Anhand vergebener Auftragskennungen läßt sich das jedoch erkennen und entsprechend darauf reagieren (vgl. Kapitel 5). Werden Anfragen an die Namensverwaltung mehrfach verteilt und liegen im Verwalternetz Replikationen von Namenseinträgen vor, so kann das akkumulierte Anfrageergebnis u.U. dieselbe Antwort mehrfach enthalten. Wo dies unerwünscht ist, lassen sich anhand der Auftragskennung und des an den Namen gebundenen Objekt-Bezeichners Duplikate eliminieren.
Voraussetzung für die Erkundung des Verwalternetzes bei der strukturunabhängigen Auflösung ist, daß dieses zusammenhängend und bidirektional ist. Diese Eigenschaft ist, vorausgesetzt es liegen keine Ausfälle vor, jedem hierarchischen Verwalternetz zuzuschreiben. Ein Namensverwalter muß außerdem Kenntnis von allen seinen benachbarten Namensverwaltern besitzen.
Ziel der vollständigen Erkundung des Verwalternetzes ist es, jeden Namensverwalter mindestens einmal zu kontaktieren. Basisalgorithmen, die sich dafür eignen, sind zum einen die Tiefensuche, zum anderen die Parallelsuche. Sowohl die Tiefen- als auch die Parallelsuche entsprechen in ihrer Grundform einer rekursiven Erkundungsstrategie. Diese zeichnet sich dadurch aus, daß besuchte Namensverwalter die Auflösung in eigener Regie so fortsetzen, als seien sie selbst der Initiator.
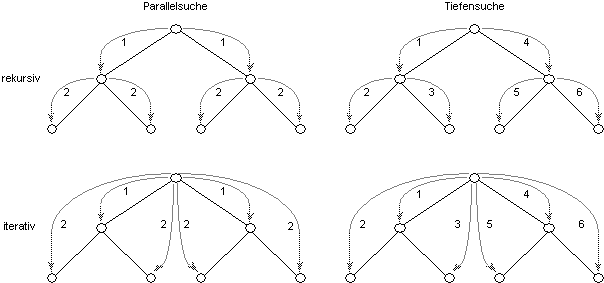
Abbildung 4.1: Erkundungsstrategien in Bäumen
Der Ablauf der Tiefensuche entspricht dabei genau dem Vorgehen, das diesem Algorithmus auch in der Graphentheorie zugrunde liegt. Existieren keine Kopien von Namenseinträgen und wird nur ein Eintrag angefordert, so kann die Tiefensuche bei Vorliegen eines Treffers abgebrochen werden. Im Mittel müssen 50% der Namensverwalter kontaktiert werden, um einen einzelnen Namenseintrag zu lokalisieren. Falls es sich jedoch um eine generische oder attributierte Anfrage handelt, sind alle Namensverwalter im Verwalternetz zu kontaktieren.
Die Parallelsuche dagegen ist eine dem hierarchischen Verwalternetz angepaßte Variante eines anderen Graphenalgorithmus, der Breitensuche. Eine eingehende Anfrage wird hierbei parallel an alle Netzwerkverbindungen weitergereicht, die von der eingehenden Verbindung verschieden sind. Auch wenn nur ein Namenseintrag lokalisiert werden soll, werden bei der iterativen Variante der Parallelsuche alle Namensverwalter im Verwalternetz kontaktiert. Dabei besteht die Gefahr der Überflutung des globalen Verwalternetzes mit Netzwerknachrichten.
Anstatt die Lokalisierung in eigener Regie fortzusetzen, kann sich die besuchte Instanz auch darauf beschränken, den Initiator durch Referenzen über bestehende Fortsetzungsmöglichkeiten zu informieren. Es obliegt dann dem Initiator der Anfrage, diese Referenzen weiterzuverfolgen und die zugehörigen Namensverwalter zu kontaktieren. Je nachdem, ob die erhaltenen Referenzen sukzessive oder parallel verfolgt werden, erhält man eine iterative Variante der Tiefen- oder Parallelsuche. Mögliche Varianten sind in Abbildung 4.1 zusammengefaßt.
Bei den rekursiven Strategien läßt sich noch weiter differenzieren, je nachdem ob die Ergebnisrückmeldung denselben Weg zurück zum Initiator der Anfrage nimmt, oder der betreffende Namensverwalter das Anfrageergebnis direkt zurücksendet. Zunächst tendiert man dazu, letztere Variante aufgrund der geringeren Anzahl von Nachrichten zu bevorzugen. Dies wäre jedoch etwas voreilig, da es sich bei einem Verwalternetz um eine logische Struktur handelt. Was im Verwalternetz als eine direkte Verbindung erscheint, kann im zugrundeliegenden physikalischen Netz über eine Vielzahl von Zwischenknoten führen, so daß Aussagen über Pfadlängen nur bedingt zur Beurteilung herangezogen werden können[AL1][AL2]. Welche der möglichen Varianten sich in der konkreten Realisierung tatsächlich bewährt, hängt nicht zuletzt von den zur Verfügung stehenden Kommunikationsmechanismen ab. Nachteilig wirkt sich das Umgehen der Zwischeninstanzen bei der Rückgabe von Anfrageergebnissen in jedem Fall dann aus, wenn Teilergebnisse von Namensanfragen in involvierten Namensverwaltern für künftige Anfragen vorgehalten werden sollen (vgl. hierzu auch Kapitel 5).
Auf einen eingehenden Vergleich und eine Analyse des Nachrichtenaufkommens der vorgestellten Verfahren wird an dieser Stelle verzichtet (vgl. hierzu [Mattes, 91]). Es bleibt festzuhalten, daß strukturunabhängige Verfahren zur Baumerkundung, insbesondere zusammen mit Verfahren zur Begrenzung der Erkundungstiefe in hierarchischen Namensräumen, bei der Lokalisierung von Namenseinträgen im Verwalternetz für generische und attributierte Namensanfragen ihren Einsatz finden, sofern im Namensraum keine eindeutige Navigationsinformation vorhanden ist, die die strukturorientierte Auflösung ermöglicht.
4.1.1.2 Strukturorientierte Namensauflösung
Die Lokalisierung von Namenseinträgen im Verwalternetz bei strukturunabhängiger Auflösung erweist sich als sehr nachrichtenintensiv und führt auch zu einer Belastung von Namensverwaltern, die für die Auflösung eines Namens nicht relevant sind. Man ist daher bemüht, die Ausbreitung von Namensanfragen durch die gezielte Auswahl von Namensverwaltern einzuschränken. Die damit verbundene Aufgabe ist vergleichbar mit der Weglenkung (routing) in vermaschten Kommunikationsnetzen. Die Namensverwalter müssen hierzu über Navigationsinformationen verfügen, anhand derer für jeden eingehenden Auftrag eine Weiterleitungsentscheidung getroffen werden kann.
Der folgende Abschnitt stellt strukturorientierte Auflösungsverfahren vor, die basierend auf der Interpretation des gesuchten Namens und der Navigationsinformation in Namensverwaltern Anfragen gezielt an den zuständigen Namensverwalter im Verwalternetz leiten. Die Navigationsinformation in Namensverwaltern gibt an, über welche Verbindung eine Partition des globalen Namensraums erreicht wird. Durch die Interpretation des Namens während der Auflösung und mit Hilfe von Navigationsinformation kann die Erkundung des Verwalternetzes gezielt gesteuert werden. Dieses Vorgehen, das auch als Navigation im Verwalternetz verstanden wird und hier nur im Ansatz formuliert ist, soll in den nächsten Abschnitten weiter präzisiert werden.

Abbildung 4.2: Schrittweise Auflösung des Namens „/a.b.c.d“ durch Remote-Pathname-Expansion
Die strukturorientierte Auflösung globaler Namen unterscheidet absolute und relative Namen (vgl. Kapitel 2.2.3.1). Man sagt, ein Name wird relativ zu einem Kontext aufgelöst, wenn der Name nur innerhalb eines bestimmten Kontexts im Namensraum Gültigkeit besitzt. Relative Namensauflösungen finden häufig in routing-orientierten Namensräumen Verwendung (vgl. [Comer, 89]). Absolute Namen liefern bei ihrer Auflösung in jedem Kontext und Namensverwalter dasselbe Ergebnis.
Ein bekanntes Verfahren zur globalen Auflösung hierarchischer Namen nach dem oben dargestellten Prinzip ist die sog. Remote Pathname Expansion [Sheltzer, 86[AL3]]. Hierbei wird bei Anfragen nach absoluten Namen (z.B. „/a.b.c.d“ in Abbildung 4.2) ausgehend vom Namensverwalter des Wurzelkontexts die Auflösung sukzessive an den Namensverwalter geleitet, der den gesuchten Namenseintrag enthält. Jeder Namensverwalter, an den eine Anfrage gerichtet ist, versucht mit Hilfe seiner lokalen Namensbasis einen weiteren Teil des Namens aufzulösen und Navigationsinformation hierfür zu ermitteln. Existiert zu einem partiellen Namen ein Verweis auf einen weiteren Namensverwalter, so wird der verbleibende Namensteil zur Auflösung an den ermittelten Namensverwalter übergeben (vgl. Abbildung 4.2). Dieser Vorgang der Auflösung wiederholt sich, bis der Namenseintrag des gesuchten Namens in einem Namensverwalter im Verwalternetz lokalisiert wurde. Schließlich wird der Name lokal vollständig aufgelöst, und der an den Namen gebundene Objekt-Bezeichner zurückgegeben.
Eine weitere Methode zur Auflösung hierarchischer Namen, das sog. Zeichenkettenersetzungsmodell, wurde von Peterson und Comer [Comer, 89] vorgestellt. Das Verfahren beruht auf der syntaxgesteuerten Interpretation von Namen, wobei sukzessive Teile des strukturierten Namens durch die Bezeichnung von Kanten im Verwalternetz ersetzt werden. Ein Name „/a.b.c.d“ wird dabei zunächst ersetzt durch den Namen „Knoten1:b.c.d“. Der Knotenname seinerseits kann wieder in einem weiteren Namensraum auf die Knotenadresse abgebildet werden. Sukzessive wird so der Name in eine Beschreibung des Weges zum administrativen Namensverwalter überführt (Knoten1:Knoten2:Knoten3:d). Diese Methode liefert eine relative Route vom initiierenden Knoten zum Verwalter des gesuchten Namenseintrags und kommt in routing-orientierten Namensräumen zur Geltung (z.B. in Profile [Peterson, 87a]).
Bei der strukturorientierten Namensauflösung kann weiter differenziert werden, je nachdem ob Namen bei der Auflösung schrittweise oder als ganzes in den gebundenen Objekt-Bezeichner abgebildet werden. Bei der ersten Methode wird bei jedem Interpretationsschritt der strukturorientierten Auflösung nicht nur die Lokation des für den Teilnamen zuständigen Namensverwalters ermittelt, sondern auch bereits ein Teil des gebundenen Objekt-Bezeichners. Voraussetzung für diese Art der Auflösung ist, daß Objekt-Bezeichner ebenfalls strukturiert aufgebaut sind, so daß eine direkte Zuordnung von Teilnamen zu Komponenten des Objekt-Bezeichners möglich ist. Diese Art der Bindung von Teilnamen findet häufig bei partitionierten Namensräumen mit fester Anzahl von Teilnamen Verwendung.
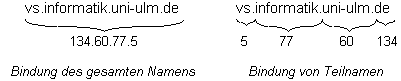
Abbildung 4.3: Bindung des gesamten Namens und Bindung von Teilnamen
Dieses Vorgehen hat jedoch den entscheidenden Nachteil, daß eine sehr starke Bindung zwischen dem globalen Namensraum und der Struktur der Objekt-Bezeichner besteht. Sind die Objekt-Bezeichner an eine physikalische Lokation gebunden, wie es beispielsweise bei IP-Adressen der Fall ist, so wäre auch der Namensraum ortsabhängig (vgl. Abbildung 4.3). Um dies zu vermeiden, findet die eigentliche Auflösung von Namen zu Objekt-Bezeichnern erst in dem Namensverwalter statt, in dem der Namenseintrag für den vollständigen Namen lokalisiert wurde (vgl. Domain Name System [Mockapetris, 84a]). Alle vorangegangenen Auflösungsschritte dienen nur der Lokalisierung dieses Namensverwalters im Verwalternetz.
4.1.1.3 Verfahren der strukturorientierten Namensauflösung
Unabhängig von der gegebenen Namenskonvention sowie unabhängig von der Topologie des Netzwerks und der Art der Verteilung können bei der strukturorientierten Namensauflösung ähnlich wie bei der strukturunabhängigen Auflösung generell rekursive, iterative und transitive Verfahren unterschieden werden. Allerdings wird hier eine gezielte Auswahl der kontaktierten Namensverwalter getroffen.
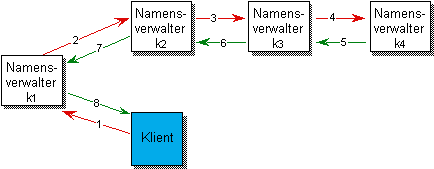
Abbildung 4.4: Rekursive Auflösung globaler Namen
Die rekursive Methode leitet in Abhängigkeit vom Namen die Anfrage von einem Namensverwalter zum nächsten. Jeder Namensverwalter versucht, einen Teil des Namens aufzulösen und den verbleibenden Namen an den hierfür zuständigen Namensverwalter weiterzugeben. Der Vorteil der rekursiven Methode liegt in der guten Verteilung der Last und der geringen Anzahl von Nachrichten[1]. Vorteilhaft ist die rekursive Methode besonders dann, wenn Namensverwalter nicht nur einen, sondern mehrere geschachtelte Kontexte verwalten, da dann ein großer Teil des Namens ohne Kommunikation mit anderen Namensverwaltern lokal aufgelöst werden kann.
Bei der iterativen Auflösung globaler Namen werden strukturierte Namen vom initiierenden Namensverwalter (Klient) selbst sukzessive abgearbeitet und der jeweils für einen Namensteil zuständige Namensverwalter direkt angesprochen. Die Ergebnisse der partiellen Namensauflösung werden direkt an den Initiator zurückgegeben. Mit der vom vorangegangenen Namensverwalter erhaltenen Navigationsinformation wird versucht, den nächsten Teil des Namens direkt beim Verwalter des zuletzt ermittelten Kontexts aufzulösen[2].
Die iterative Methode hat den Vorteil, daß sie das Vorhalten von Namenseinträgen im Klienten erleichtert, da alle Teilergebnisse der Auflösung zu diesem zurückgegeben werden. Da von Namensverwaltern mehrere Kontexte verwaltet werden können, ist es sinnvoll, iterativ nicht einzelne Namensbestandteile anzufragen, sondern immer den restlichen, noch nicht aufgelösten Namen.
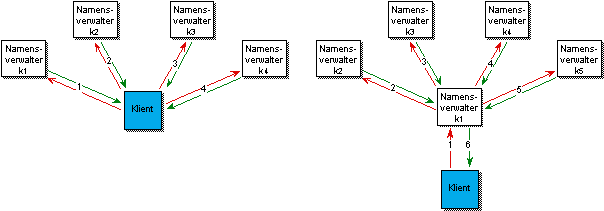
Abbildung 4.5: Iterative Auflösung globaler Namen
Eine mögliche Variante der iterativen Auflösung globaler Namen besteht im Kontaktieren eines regionalen Namensverwalters durch den Klienten, wobei der Name vom regionalen Namensverwalter aufgelöst wird und nur das endgültige Resultat der Anfrage an den Klienten zurückgegeben wird. Der Vorteil dieses Vorgehens besteht darin, daß durch das Vorhalten einmal aufgelöster Namensteile im regionalen Namensverwalter diese auch für die Auflösung von Namen durch andere Klienten zur Verfügung stehen.
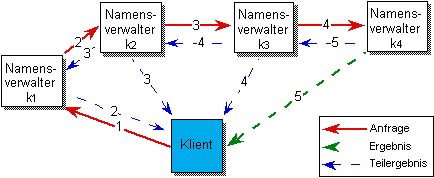
Abbildung 4.6: Transitive Auflösung globaler Namen mit Rückgabe von Teilergebnissen
Den geringsten Nachrichtenaufwand zur der Auflösung globaler Namen erfordert die transitive Methode. Die Anzahl der Nachrichten beträgt lediglich n+1, wobei n der Anzahl der kontaktierten Namensverwalter entspricht. Dies bedeutet jedoch nicht, daß sich die Auflösungszeit notwendigerweise im selben Maße verringert, da die Rückmeldung, auch wenn sie ihren Weg nicht durch die einzelnen Namensverwalter zurück nimmt, u.U. dennoch mehrere Teilnetze zu durchlaufen hat. Die transitive Methode entlastet jedoch in jedem Fall die Zwischeninstanzen von der Bearbeitung von Rückmeldungen, die in vielen Systemen einen zeitaufwendigen Prozeßwechsel erfordert. Da die involvierten Namensverwalter die Nachrichten nicht durchreichen müssen, verringert sich die für die Auflösung benötigte Zeit, so daß die transitive Variante dennoch als effektivste Methode betrachtet werden kann. Durch die transitive Auflösung wird zudem eine gleichmäßige Verteilung der Last auf die involvierten Namensverwalter erreicht.
Die reine Form der transitiven Auflösung hat allerdings den Nachteil, daß keine Zwischenergebnisse für das Vorhalten von Namenseinträgen an die beteiligten Namensverwalter zurückgeliefert werden.[AL4] Eine mögliche Variante der transitiven Auflösung sieht daher vor, zusätzlich Teilergebnisse direkt zum vorhergehenden Namensverwalter oder zum Initiator der Anfrage zum Zwecke des Vorhaltens zurückzugeben (vgl. Kapitel 5). Die Anzahl der für die Namensauflösung notwendigen Nachrichten bleibt dabei unverändert, da diese unabhängig von den Rückmeldungen parallel versendet werden (vgl. Abbildung 4.6)[3].
4.1.2 Zusammenspiel verschiedener Auflösungsverfahren
In Kapitel 2 wurden Verfahren zur lokalen Auflösung hierarchischer Namen vorgestellt. Die vorangegangenen Abschnitte zeigten Methoden zur Auflösung globaler Namen auf. Um eine globale Namensauflösung über Verwaltergrenzen hinweg zu realisieren, die auch in der Lage ist, generische und attributierte Namen aufzulösen, sind diese Verfahren geeignet miteinander zu kombinieren. Der nachfolgende Abschnitt beschreibt das Zusammenspiel der vorgestellten Auflösungsmethoden.
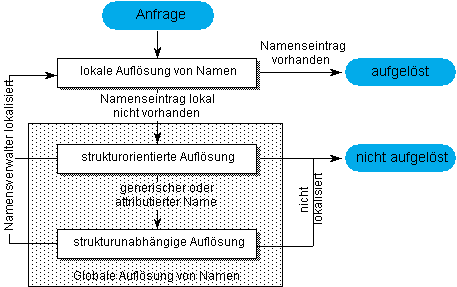
Abbildung 4.7: Zusammenspiel verschiedener Verfahren zur Auflösung von Namen
Wie in Abbildung 4.7 dargestellt, verläuft die Auflösung globaler Namen mehrstufig. Ausgehend von einem hierarchischen Namen beginnt die Suche nach dem zugehörigen Namenseintrag zunächst lokal. Dabei wird die lokale bzw., in Präsenz einer Rechnerkopplung über DSM, die verbundweite Namensbasis durchsucht (vgl. [Lupper, 94]). In der lokalen Namensbasis sind eventuell auch vorgehaltene Ergebnisse früherer globaler Auflösungen vorhanden, die auf externe Namensverwalter verweisen.
Bleibt die lokale Auflösung erfolglos, so werden in die Auflösung externe Namensverwalter miteinbezogen. Dazu wendet sich der lokale Namensverwalter zunächst an den obersten Namensverwalter der Verwalterhierarchie. Ausgehend vom obersten Namensverwalter wird versucht, den Namen zu interpretieren und anhand der vorliegenden Navigationsinformation für Teilnamen zuständige Namensverwalter zu lokalisieren. Erkennt die strukturorientierte Auflösung des Namens generische oder attributierte Teilnamen, die keine Navigation im Verwalternetz ermöglichen, so werden diese mittels strukturunabhängiger Verfahren aufgelöst. Die strukturunabhängige Lokalisierung des gesuchten Namenseintrags beschränkt sich dabei auf den Teil des Verwalternetzes, der den durch den bereits aufgelösten Teilnamen bestimmen Unterbaum des hierarchischen Namensraums enthält. Die strukturunabhängige Lokalisierung von Namenseinträgen wird dabei in ihrer Tiefe durch nachfolgende, nicht generische Namensteile beschränkt und sobald wie möglich strukturorientiert fortgesetzt (vgl. Abbildung 4.7). Wurde der Name vollständig interpretiert und ist der zugehörige Namenseintrag im lokalisierten Namensverwalter vorhanden, so wird der an den Namen gebundene Objekt-Bezeichner an den initiierenden Namensverwalter zurückgegeben.
Ergebnisse einer globalen Auflösung werden für eine bestimmte Zeit lokal vorgehalten, um bei erneuten Anfragen die Zugriffszeit zu reduzieren. Führt das Verfolgen externer vorgehaltener Referenzen nicht zum gewünschten Erfolg, so werden diese aus der lokalen Namensbasis entfernt (vgl. Kapitel 5). Falls keine lokal vorgehaltenen Verweise existieren oder diese nicht zum gewünschten Erfolg führen, leitet die Namensverwaltung die globale Auflösung ein.[AL5]
Die Lokalisierung von Namenseinträgen im Verwalternetz hat entscheidenden Einfluß auf die Effektivität globaler Namensverwaltungen. Die transitive Auflösung und die sukzessive Ausdehnung des Suchraums erhöhen die Effizienz und Flexbilität der globalen Namensauflösung.
4.2 Verteilung und Plazierung globaler Namen
Prinzipiell sind zur Verwaltung globaler Namensräume sowohl zentrale als auch dezentrale Verfahren (vgl. Kapitel 3) denkbar. Aufgrund der mangelnden Skalierbarkeit scheiden zentrale Verfahren zur globalen Namensverwaltung allerdings aus. Wie in Kapitel 2 und 3 weiter gezeigt wurde, sind hierarchische Verwalternetze und Namensräume aufgrund ihrer hohen Skalierbarkeit und der Effizienz der strukturorientierten Namensauflösung für die globale Namensverwaltung prädestiniert. Der folgende Abschnitt beschränkt sich daher auf die Verteilung hierarchischer Namensräume auf hierarchische Verwalternetze.
Bei der Registrierung eines globalen Namens im Verwalternetz sind folgende Fragestellungen zu klären:
• Wie wird ein neuer Name für ein Objekt generiert?
• Wie wird, falls erforderlich, die Eindeutigkeit von Namen gewährleistet?
• Wie geschieht die Auswahl des für einen Namen zuständigen Namensverwalters?
• Wie ist der Namensraum adäquat zu partitionieren, und wie werden die Partitionen des Namensraumes auf die Namensverwalter verteilt?
Eine entscheidende Frage bei der Registrierung hierarchischer Namen ist die Art der globalen Verteilung hierarchischer Namensräume auf die verwaltenden Instanzen im hierarchischen Verwalternetz (vgl. Abbildung 4.8).
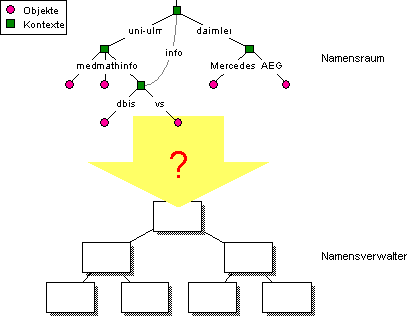
Abbildung 4.8: Problem der Verteilung hierarchischer Namensräume auf hierarchische Verwalternetze
Grundsätzlich können im Verwalternetz entweder Namenseinträge mit der Namen-Objekt-Bindung selbst (als Kopien des primären Namenseintrags) oder mit Navigationsinformation, die auf den Verwalter des primären Namenseintrags verweist, verteilt werden. Zur Verteilung globaler Namen auf die Namensverwalter einer hierarchischen Namensverwaltung kommen sowohl deterministische Verfahren als auch nicht-deterministische Verfahren in Betracht (vgl. Abbildung 4.9).
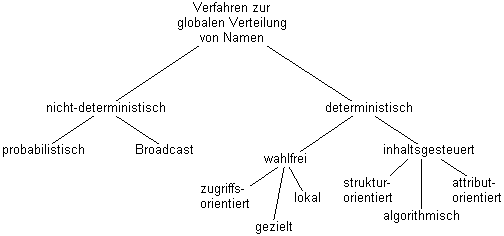
Abbildung 4.9: Methoden zur Verteilung der Namensinformation im Verwalternetz
Nicht-deterministische Verfahren, wie Broadcast-Verfahren oder probabilistische Verfahren, verteilen Namen willkürlich auf alle Namensverwalter. Deterministische Verfahren hingegen treffen eine Auswahl der Namensverwalter und verteilen Namen wahlfrei oder inhaltsgesteuert nur an bestimmte Namensverwalter.
Bevor die einzelnen Verfahren zur Verteilung globaler Namenseinträge im Verwalternetz eingehender diskutiert werden können (vgl. Abbildung 4.9), müssen zunächst Kriterien zur Beurteilung der Güte der Plazierung von Namenseinträgen im Verwalternetz aufgestellt werden.
4.2.1 Kriterien zur Plazierung von Namenseinträgen in Verwalternetzen
Die Plazierung von Namenseinträgen im Verwalternetz beeinflußt sowohl die Effizienz der mit der globalen Namensauflösung verbundenen Lokalisierung von Namenseinträgen im Verwalternetz als auch die Ausfallsicherheit der Namensverwaltung. Zur Beurteilung der Güte der Plazierung globaler Namen können folgende Kriterien dienen:
· Effizienz der Namensauflösung: Namenseinträge sollen so im Verwalternetz plaziert sein, daß eine effiziente Auflösung von Namen in wenigen Navigationsschritten erfolgen kann. Sofern die Lokalisierung durch Navigation erfolgt, soll die Anzahl der notwendigen Netzwerknachrichten und die für die Namensauflösung benötigte Zeit durch präzise Navigationsinformationen in Namenseinträgen reduziert werden. Namenseinträge sollen dabei möglichst so im Verwalternetz plaziert sein, daß die Namensauflösung für lokale Objekte nur lokale Namensverwalter kontaktiert. Außerdem sollten Namenseinträge dort verwaltet werden, wo sie am häufigsten zugegriffen werden.
· Belastung der Namensverwalter: Namenseinträge sollen so im Verwalternetz verteilt sein, daß sich eine gleichmäßige Verteilung der Last über alle Namensverwalter ergibt. Die Belastung von Namensverwaltern ergibt sich zum einen durch die Speicherung der Namenseinträge zum anderen durch die Bearbeitung von Anfragen. Der Speicherbedarf von Namensverwaltern kann reduziert werden, indem Namen zu Kontexten zusammengefaßt werden und anstatt einzelner Namenseinträge solche mit Navigationsinformationen für Kontexte verwaltet werden. Besonders Namensverwalter der oberen Ebenen hierarchischer Verwalternetze sind stark durch Anfragen belastet. Eine geeignete Plazierung von Namenseinträgen verbunden mit dem Vorhalten von Anfrageergebnissen (vgl. Kapitel 5) kann zu deren Entlastung beitragen.
· Ausfallsicherheit der Namensverwaltung: Namenseinträge müssen so im Verwalternetz verteilt sein, daß der Ausfall einzelner Namensverwalter und Kommunikationsverbindungen die Funktionsfähigkeit der Namensverwaltung möglichst wenig beeinträchtigt. Positiv auf die Ausfallsicherheit wirkt sich aus, wenn Namenseinträge dort verwaltet werden, wo sie am häufigsten zugegriffen werden. Ferner sollte gewährleistet sein, daß sofern das Objekt erreichbar ist, auch der zugehörige Name aufgelöst werden kann.
· Aktualität der
Namenseinträge: Bei der Plazierung von Namenseinträgen
im Verwalternetz ist die Frequenz der Änderungen von Namenseinträgen zu
berücksichtigen. Namenseinträge, die häufigen Änderungen unterworfen sind,
sollten möglichst nicht als Kopien im Verwalternetz verteilt werden.
Namenseinträge mit langlebigen Bindungen können einen hohen Replikationsgrad
aufweisen. Namenseinträge mit Navigationsinformationen, die auf den primären
Verwalter eines Namenseintrags verweisen, sind von Änderungen nur dann
betroffen, wenn der Namenseintrag entfernt in einem anderen Verwalter erneut
registriert wird.
Bevor die Verteilung globaler Namenseinträge im hierarchischen Verwalternetz durch die dynamische globale Namensverwaltung beschrieben wird, sollen in den nächsten Abschnitten die in Abbildung 4.9 aufgezeigten Verfahren zur Verteilung globaler Namensräume auf Namensverwalter anhand obiger Kriterien auf ihre Verwendbarkeit für die globale Namensverwaltung untersucht werden.
4.2.2 Nicht-deterministische Verfahren zur globalen Verteilung von Namen
Nicht-deterministische Verfahren zur Verteilung von Namensinformationen im Verwalternetz stützen sich häufig auf Broadcast-Verfahren. Werden Namensverwalter durch ein Kommunikationsmedium mit Rundspruchfähigkeit verbunden, so bietet sich zumindest im lokalen Netzwerkbereich der Einsatz von Broadcast-Nachrichten an, um Namenseinträge innerhalb des Broadcast-Bereichs an alle Namensverwalter zu propagieren und die Eindeutigkeit von Namen zu prüfen (vgl. auch Abschnitt 3.2).
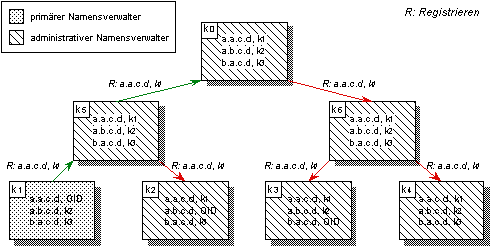
Abbildung 4.10: Nicht-deterministische Verteilung von Namenseinträgen mit Navigationsinformation
Bei der vollständigen Replikation von Namenseinträgen können entweder Kopien des primären Namenseintrags, die die Bindung des Namens zum Objekt enthalten, oder Namenseinträge mit Navigationsinformation, die auf den primären Namenseintrag verweist, im hierarchischen Verwalternetz verteilt werden (vgl. Abbildung 4.10). Letztere Methode hält die Bindung des Namens zum Objekt nur im primären Namensverwalter, während sich in administrativen Namensverwaltern lediglich Verweise auf den primären Eintrag befinden.
Die Verteilung von Kopien primärer Namenseinträge hat den Nachteil, daß, um die Aktualität der Namenseinträge zu gewährleisten, bei jeder Änderung der Bindung zum Objekt der Namenseintrag erneut an alle Namensverwalter propagiert werden muß. Namenseinträge mit Navigationsinformationen hingegen müssen bei Änderungen nicht aktualisiert werden, erfordern jedoch einen zusätzlichen Indirektionsschritt bei der Auflösung von Namen, da die Bindung zum Objekt nicht direkt verfügbar ist.
Broadcast-Verfahren haben allerdings mehrere Nachteile, die ihre Nützlichkeit für die globale Namensverwaltung einschränken:
· Broadcast-Nachrichten überschwemmen auch Netzwerkbereiche, die für die Auflösung des Namenseintrags nicht relevant sind. Hierdurch entsteht systemweit kurzzeitig ein hohes Nachrichtenaufkommen und eine starke Belastung des Netzwerks.
· Broadcast-Nachrichten können über Punkt-zu-Punkt-Verbindungen nur iterativ verteilt werden.
· Broadcast-Nachrichten verursachen eine starke Belastung der beteiligten Namensverwalter, da jeder Verwalter einen Prozeß startet, um die Anfrage zu prüfen, unabhängig davon, ob er zur Auflösung des Namenseintrags beitragen kann oder nicht.
In Analogie zur strukturunabhängigen Namensauflösung in Abschnitt 4.1.1.1 können auch iterative Verfahren zur nicht-deterministischen Verteilung von Namen in Betracht gezogen werden. Diese reduzieren die temporäre Belastung des Netzwerk (Burst), nicht jedoch das Nachrichtenaufkommen. Außerdem dauert die Verteilung von Namensinformationen erheblich länger, was sich wiederum nachteilig auf die Aktualität der Namenseinträge auswirkt.
Um die Nachteile von Broadcast-Verfahren zu vermeiden und dennoch eine vollständige Informationsverteilung zu erreichen, wurde von Drezner und Barak [Drezner, 85] [Drezner, 86] erstmals die probabilistische Verteilung von Namen vorgeschlagen. In diesem Ansatz wird versucht, durch die zufällige Auswahl von Namensverwaltern eine zeitlich gleichmäßige Verteilung der Last von Update-Nachrichten zu erreichen. Jeder Namensverwalter gleicht dabei periodisch mit einer zufällig ausgewählten Instanz seine Namensbasis ab, so daß gewährleistet ist, daß nach einer bestimmten Zeit mit hoher Wahrscheinlichkeit eine Änderung vollständig propagiert wurde und jeder Namensverwalter denselben Informationsstand besitzt. Dieses Vorgehen erscheint vor allem dann angemessen, wenn nur selten Änderungen der globalen Namensbasis auftreten. Bei hoher Modifikationsfrequenz globaler Namenseinträge besitzt die Namensbasis jedoch oftmals nicht die geforderte Aktualität.
Auf eine eingehende Diskussion dieser Verfahren zur Verteilung von Namenseinträgen soll an dieser Stelle verzichtet werden. Der interessierte Leser findet diese zusammen mit zusätzlichen Vorschlägen zur Steigerung der Fehlertoleranz in Kapitel 5 und in [Mattes, 91].
4.2.3 Deterministische Verfahren zur globalen Verteilung von Namen
Die bisher beschriebenen Methoden zur nicht-deterministischen Verteilung von Namensinformation plazieren Namenseinträge im Verwalternetz, ohne den Inhalt der Namen und die Struktur des Namensraums zu berücksichtigen. Deterministischen Verfahren zur Plazierung von Namen können hingegen unterteilt werden in wahlfreie Verfahren, die Namenseinträge unabhängig von ihrem Inhalt plazieren, und inhaltsgesteuerte Verfahren, die den Inhalt der Namenseinträge bei der Plazierung im Verwalternetz berücksichtigen:
· Wahlfreie Plazierung
· Lokale Plazierung am Entstehungsort: Der zugehörige Namenseintrag wird stets dort abgelegt, wo der Name registriert wurde.
· Gezielte und zugriffsorientierte Plazierung: Der für einen Namenseintrag zuständige Namensverwalter kann bei der Registrierung eines Namens explizit angegeben werden. Namenseinträge werden bevorzugt dort im Verwalternetz plaziert, wo sie nach den zu erwartenden Zugriffsmustern am häufigsten angefragt werden.
·
Inhaltsgesteuerte
Plazierung
· Algorithmische Plazierung: Der Verwalter zur Plazierung eines Namenseintrags wird durch eine Auswahlfunktion aus dem Namen bestimmt.
· Attributorientierte Plazierung: Namenseinträge werden anhand bestimmter Attribute oder Attributwerte auf Namensverwalter verteilt.
· Strukturorientierte Plazierung: Namen werden durch die Auswahl syntaktischer Merkmale auf Namensverwalter im Verwalternetz verteilt.
Die inhaltsgesteuerten Methoden zur Verteilung von Namen im Verwalternetz erlauben die selbständige Verteilung und Plazierung von Namen auf Namensverwaltern im Verwalternetz durch die Namensverwaltung. Nachfolgende Abschnitte wenden sich nun speziell diesen Verteilungsverfahren zu.
4.2.3.1 Lokale Plazierung von Namen in Namensverwaltern
Die lokale Plazierung von Namenseinträgen in den registrierenden Namensverwaltern bewirkt eine vollständige Verteilung von Namenseinträgen im Verwalternetz. Sofern die Eindeutigkeit nicht durch administrative Maßnahmen gewährleistet ist, muß bei der Registrierung das gesamte Verwalternetz nach gleichen Namen durchsucht werden. Eine vollständige Erkundung des Verwalternetzes wird ebenfalls bei der Auflösung globaler Namen notwendig. Hierzu können Broadcast-Verfahren oder andere in Abschnitt 4.1 vorgestellte Verfahren zur vollständigen Erkundung hierarchischer Verwalternetze herangezogen werden.
Um die vollständige Erkundung des Verwalternetzes bei der vollständigen Verteilung und den zusätzlichen hohen Speicherbedarf der totalen Replikation von Namenseinträgen zu vermeiden, bietet sich zunächst eine Vorgehensweise an, bei der jeder Namensverwalter entweder Kopien seiner primären Namenseinträge oder Namenseinträge mit Navigationsinformation für von ihm verwaltete Namenseinträge an übergeordnete Namensverwalter weitergibt (vgl. Abbildung 4.11). Dadurch befinden sich in den Namensbasen übergeordneter Namensverwalter jeweils die Vereinigungsmengen der Namensinformationen untergeordneter Namensverwalter.

Abbildung 4.11: Aufsteigende Verteilung der Namenseinträge
Ein Vorteil der in Abbildung 4.11 vorgestellten Art der Propagierung von Namenseinträgen ist, daß nicht jeder Namensverwalter alle Informationen halten muß. Bei der Auflösung von Namen wird spätestens in der Wurzel der Verwalterhierarchie der gesuchte Namenseintrag oder Navigationsinformation auf den primären Namenseintrag lokalisiert, sofern sich untergeordnete Namensverwalter zur Namensauflösung schrittweise jeweils an den übergeordneten Namensverwalter wenden.
Als Nachteil ist zu sehen, daß nur einige wenige Namensverwalter die Gesamtheit aller Kontexte enthalten und dadurch das System sensibel auf Ausfälle dieser Namensverwalter reagiert. Als besonders nachteilig erweist sich, daß die in der Verwalterhierarchie höher eingestuften Namensverwalter sowohl durch die Quantität der zu verwaltenden Namenseinträge als auch durch die hohe Frequentierung durch Anfragen stark belastet sind. Diese Methode ist daher nur praktikabel, falls Namen verstärkt in dem Bereich des hierarchischen Verwalternetzes aufgelöst werden, in dem sie registriert werden. Andernfalls wird in die Auflösung immer die Wurzel der Verwalterhierarchie einbezogen. Die Belastung übergeordneter Namensverwalter kann u.U. durch das Vorhalten häufig verwendeter Namenseinträge in untergeordneten Namensverwaltern reduziert werden.
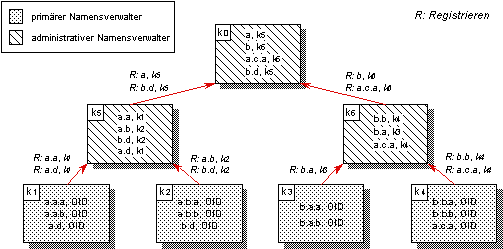
Abbildung 4.12: Aufsteigende Verteilung mit Kontextbildung
Betrachtet man die Namenseinträge in den untersten Namensverwaltern in Abbildung 4.12, so ist festzustellen, daß die Anzahl der zu verwaltenden Namenseinträge in den oberen Ebenen der Verwalterhierarchie reduziert werden kann, indem ähnliche Namen zu Kontexten zusammengefaßt werden. In den übergeordneten Namensverwaltern werden nur Namenseinträge mit Verweisen auf diese Kontexte verwaltet. Durch diese einfache Art der Kontextbildung ist jedoch die Eindeutigkeit der Kontexte im Verwalternetz nicht gewährleistet, da sich dieselben Kontexte in unterschiedlichen Teilen des Verwalternetzes bilden können. Bei Mehrdeutigkeiten in der Navigationsinformation folgt die Navigation bei der strukturorientierten Namensauflösung mehreren Pfaden im Verwalternetz.
Ein Verfahren zur eindeutigen Kontextbildung und zur Verteilung von Namenseinträgen auf Namensverwalter wird in Abschnitt 4.3 vorgestellt.
4.2.3.2 Gezielte und zugriffsorientierte Plazierung globaler Namen
Bei der gezielten Plazierung von Namenseinträgen hat der registrierende Benutzer die Wahl unter mehreren Namensverwaltern. Die gezielte Plazierung wird allgemein dann verwendet, wenn eigentlich eine lokale Ablage anstrebt wird, man jedoch aus Leistungs- und Konfigurationsgründen gezwungen ist, im Administrationsbereich mehrere Namensverwalter zu installieren. Durch eine gezielte Zuordnung der anfallenden Namenseinträge kann für eine gleichmäßige Auslastung der Namensverwalter gesorgt werden. Die Zielinstanz wird entweder in einem zusätzlichen Parameter bestimmt, oder sie ist in einer benutzer- oder installationsspezifischen Umgebungsvariablen definiert.
Wird bei der Verteilung von Namenseinträgen auf Namensverwalter berücksichtigt, wo die registrierten Namenseinträge am häufigsten zugegriffen werden, so spricht man von einer zugriffsorientierten Plazierung von Namenseinträgen im Verwalternetz. Verschiedene zugriffsorientierte Verfahren für das Verteilungsproblem von Attributen auf verteilte Datenbankrechner bietet die Theorie der verteilten Datenbanken an [Apers, 88]. Diesen Verfahren ist jedoch allen gemeinsam, daß basierend auf den zu erwartenden Zugriffsmustern der Klienten eine optimale Partitionierung einer Relation bestimmt wird. Für Namensverwaltungen lassen sich jedoch zum Zeitpunkt der Registrierung kaum Vorhersagen für die zu erwartenden Zugriffsmuster treffen, so daß aus der Datenbanktechnik bekannte Verfahren hier nicht greifen. Es kann lediglich festgestellt werden, daß Namen sehr häufig in der unmittelbaren Netzwerk-Umgebung der gebundenen Objekte aufgelöst werden. Namen sollten daher immer auch zumindest als Kopien am Verwaltungsort des gebundenen Objekts abgelegt werden. Eine Optimierung der Anfragebearbeitung, die den veränderlichen Zugriffsmustern in globalen Namensverwaltungen gerecht wird, kann nur durch vorgehaltene Namenseinträge erreicht werden (vgl. hierzu Kapitel 5).
Neben den wahlfreien Verfahren zur gezielten und zugriffsorientierten Plazierung globaler Namen kann diese auch jeweils abhängig vom jeweiligen Namen erfolgen. Beide Formen der Plazierung zeichnen sich durch einen geringen Kommunikationsaufwand aus. Der Namenseintrag kann direkt an den zuständigen Namensverwalter übergeben werden. Sofern in der Namensverwaltung keine Navigationsinformation geführt wird, können Namenseinträge global jedoch nur durch streuende Verfahren lokalisiert werden. Sowohl bei der gezielten als auch bei der zugriffsorientierten Plazierung globaler Namen können konkurrierende Registrieroperationen auftreten. Kann der damit verbundene Konflikt nicht durch die eindeutige Zuordnung eines Namensverwalters zu einem Namen aufgelöst werden, so ist zur Gewährleistung der Eindeutigkeit von Namen jeder Namensverwalter zu kontaktieren.
4.2.3.3 Algorithmische Verteilung globaler Namen auf Namensverwalter
Besitzt ein zu verwaltender Namensraum keine Struktur, wie dies z.B. bei flachen Namensräumen der Fall ist, oder soll die Verteilung der Namen auf Namensverwalter sich aus irgendwelchen Gründen, die außerhalb der Namensverwaltung zu suchen sind, nicht strukturorientiert erfolgen, so bleibt letztendlich nur die algorithmische Aufteilung des Namensraums. Die Eignung algorithmischer Verteilungsverfahren richtet sich im wesentlichen danach, ob sie es erlauben, ausgehend von einem beliebig vorgegebenen Namen den zuständigen Namensverwalter zu bestimmen, wenn als Auswahlinformation ausschließlich der Name selbst zur Verfügung steht. Dabei kann die zu treffende Auswahl durchaus in mehreren Schritten erfolgen, was sich in einem hierauf aufbauenden Verfahren lediglich im Weiterleitungsverhalten niederschlägt.
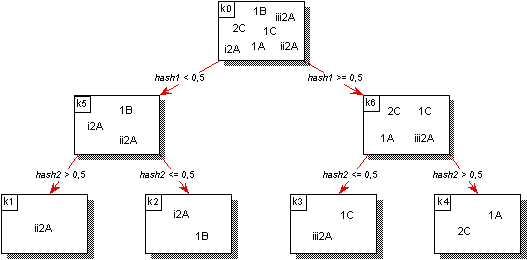
Abbildung 4.13: Verteilung der Namensinformation durch Hashing
An die Stelle der Teilbäume hierarchischer Namensräume treten bei der algorithmischen Aufteilung sog. Namenskomplexe. Ein Namenskomplex repräsentiert zunächst nur eine Teilmenge eines irgendwie gearteten Namensraums. Seine Verwendung setzt allerdings voraus, daß diese Teilmenge in irgendeiner Form algorithmisch faßbar ist. Daher werden als Namenskomplexe genauer nur diejenigen Teilmengen eines Namensraum bezeichnet, die durch eine Auswahlfunktion definiert sind (vgl. hierzu [Mattes, 91]).
Gibt man eine beliebige Folge von Auswahlfunktionen (f1, f2,…, fk) vor, so ist damit eine Aufteilung des Namensraums festgelegt. Man erhält die Namenskomplexe NK1, NK2,…,NKk und die Restmenge NK0, die alle Namen enthält, die in keiner der übrigen Mengen enthalten sind. Die so erhaltenen Mengen NK müssen jedoch nicht disjunkt sein. Eine derartige Forderung würde die Administration erheblich erschweren, da beim Hinzufügen einer neuen Auswahl deren Disjunktheit zu den bestehenden garantiert werden müßte. Um dennoch zu einer eindeutigen Zuordnung zu gelangen, behilft man sich, indem eine Ordnung auf den Auswahlfunktionen eingeführt wird (vgl. hierzu [Mattes, 91]). Das hier zunächst für den Namensraum formulierte Aufteilungsprinzip kann nun in gleicher Weise auch wieder auf die einzelnen Namenskomplexe angewendet werden. Man erkennt hierin ein Aufteilungsprinzip, das dem der Teilbäume ähnlich ist (vgl. Abbildung 4.13). Auch hier muß keine Unterscheidung zwischen der Behandlung des Namensraums insgesamt und der aus ihm hervorgehenden Teile getroffen werden. Durch die Wahl der Auswahlfunktion läßt sich nahezu jedes beliebige Aufteilungsmuster eines Namensraums realisieren. Zwei wichtige Klassen von Auswahlfunktionen sind zum einen die, die sich auf syntaktische Merkmale stützen, und zum anderen jene, die auf geeigneten Hash-Funktionen beruhen. Abbildung 4.13 zeigt die algorithmische Aufteilung eines Namensraums auf Namensverwalter anhand einer Hash-Funktion.
4.2.3.4 Attributorientierte Verteilung und Plazierung globaler Namen
Die Partitionierung eines attributierten Namensraums kann, wie in verteilten Datenbanken üblich, horizontal und vertikal geschehen. Die vertikale Partitionierung verteilt einzelne Attribute auf unterschiedliche Namensverwalter, während die horizontale Partitionierung Namenseinträge aufgrund des Wertes bestimmter Attribute Namensverwaltern zuordnet.
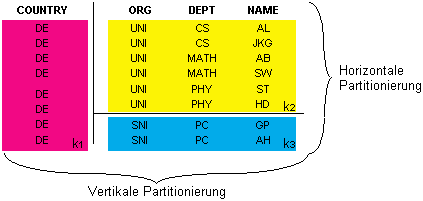
Abbildung 4.14: Horizontale und vertikale Partitionierung anhand von Attributen
Im Beispiel aus Abbildung 4.14 findet sich sowohl eine horizontale als auch eine vertikale Partitionierung. Das Attribut „Country“ wird nach der vertikalen Partitionierung dem Namensverwalter k1 zugeordnet. Alle Werte dieses Attributs befinden sich dann auf k1. Das Attribut „ORG“ hingegen wird horizontal partitioniert und anhand der Attributwerte auf die Namensverwalter k2 und k3 verteilt.
Bei attributorientierter Verteilung erfolgt die Zuordnung bestimmter Attribute bzw. Attributwerte zu Namensverwaltern administrativ zum Zeitpunkt der Einrichtung der Namensverwaltung. Eine zugriffsorientierte Verteilung der Attribute bzw. Attributwerte, wie bei der Partitionierung und Verteilung von Relationen in verteilten Datenbanken üblich, ist im Falle von Namensverwaltungen nicht vorteilhaft, da die zu erwartenden Zugriffsmuster in Namensverwaltungen i.a. nicht a priori bekannt sind.
4.2.3.5 Syntaxorientierte Verteilung von Namen auf Namensverwalter
Die inhaltsgesteuerte Plazierung von Namenseinträgen im Verwalternetz kann als Pendant zu den nicht-deterministischen und wahlfreien Verfahren betrachtet werden. Waren diese von der vollständigen Replikation bzw. Verteilung der Namenseinträge geprägt, so ist das entsprechende Merkmal hier die Segmentierung des Namensraums.[AL6][AL7]
An Informationen zur Auswahl eines Namensverwalters bei der syntaxorientierten Verteilung steht nur der Name zur Verfügung. Die Plazierung anhand des Namens setzt notwendig voraus, daß die Zuständigkeit für die jeweiligen Namen örtlich konzentriert ist. Der zuständige Namensverwalter wird allein aufgrund der syntaktischen Zusammensetzung des Namens gewählt.
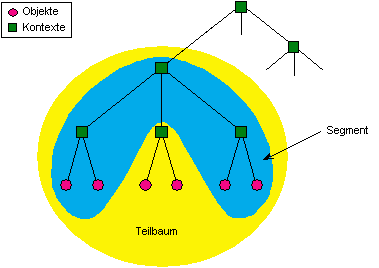
Abbildung 4.15: Aufteilung eines hierarchischen Namensraums in Segmente
Voraussetzung für die syntaxorientierte Plazierung von Namenseinträgen in Namensverwaltern ist die Segmentierung des Namensraums. Liegt ein hierarchischer Namensraum vor, so kann sich eine Segmentierung beispielsweise wie in Abbildung 4.15 darstellen. Segmente bestehend aus Unterbäumen des hierarchischen Namensraums werden administrativ Namensverwaltern zugeordnet. Die Verbindung zwischen den einzelnen Segmenten des Namensraums wird durch Namenseinträge mit Navigationsinformation in Namensverwaltern übergeordneter Segmente hergestellt. Jedes Segment des Namensraums muß ausgehend von der Wurzel der Verwalterhierarchie durch Navigation erreichbar sein. Neu hinzukommende Namen können nun anhand ihrer Struktur Segmenten zugeordnet und in den hierfür zuständigen Namensverwaltern plaziert werden.
Stimuliert durch die „directory“-Konzepte lokaler Systeme und insbesondere durch UNIX hat sich die Plazierung anhand des Namens quasi zum Standard entwickelt. Fast alle bis heute vorgeschlagenen und realisierten Namensverwaltungen, u.a. Grapevine, Clearinghouse, das Domain Name System und auch X.500 setzten auf die Plazierung anhand des Namens.
Die Segmentierung des Namensraums und die Zuordnung der Segmente zu Namensverwaltern ist das entscheidende Problem bei der syntaxorientierten Verteilung von Namen im Verwalternetz. Bei Systemen mit statischem Namensraum, wie z.B. Grapevine oder Clearinghouse, ist die Segmentierung und die Zuordnung von Namensraumsegmenten zu Namensverwaltern noch relativ einfach. Sehr viel schwieriger gestaltet sich die Verteilung, wenn der Namensraum beliebig erweiterbar ist. Das Domain Name System und X.500 sind Beispiele hierfür. Ohne zusätzliche Vorkehrungen ist man bei diesen Systemen weder in der Lage, die Einhaltung vorgeschriebener Namenskonventionen zu garantieren noch eine konsistente Verteilung der Namenseinträge auf Namensverwalter zu erreichen. Im Domain Name System wird dieser Umstand durch die unterschiedliche Namensraumstruktur in Domains deutlich (z.B. uni-ulm.de, uni-linz.ac.at, stanford.edu). Diese Erkenntnis hat in X.500 dazu geführt, daß sogenannte „Structure Rules“ eingeführt wurden, die die zulässigen Typhierarchien im Directory Information Tree festschreiben und eine einheitliche Verteilung der Namensraumsegmente auf Namensverwalter regeln.
Traditionelle Namensverwaltungen orientieren sich bei der Segmentierung und Verteilung von Namen im Verwalternetz an folgendem Leitsatz:
„The distribution reflects the logical distribution of
the directory information tree“
Eine derartige Segmentierung läßt oftmals anhand der Namensstruktur die Namensverwaltergrenzen deutlich erkennen. Anwender sollten jedoch bei der Benennung von Objekten auf logische Namen zurückgreifen können, die unabhängig von der physikalischen oder organisatorischen Organisation des Netzwerks sind. Eine starre, an organisatorischen oder physikalischen Strukturen orientierte Segmentierung wird den differenzierten Anforderungen der Anwender zur individuellen Gestaltung des Namensraums nicht gerecht.
Die dynamische globale Namensverwaltung plaziert daher logische Namen selbständig anhand ihrer syntaktischen Struktur im Verwalternetz. Die Segmentierung des Namensraums wird dabei nicht administrativ anhand physikalischer oder organisatorischer Strukturierungsmerkmale des Namensraums vorgenommen, sondern erfolgt selbständig. Namensraumsegmente und die für die Lokalisierung von Namenseinträgen notwendige Navigationsinformation bilden sich selbständig durch die syntaxorientierte Plazierung von Namen im Verwalternetz. Ein Verfahren zur Plazierung globaler Namen anhand ihrer syntaktischen Struktur und zur Generierung der die Namensraumsegmente verbindenden Navigationsinformation wird in Abschnitt 4.3 vorgestellt.
4.2.4 Granularität von Namensraumsegmenten
Der folgende Abschnitt versucht, den quantitativen Aspekt der Verteilung zu fassen. Schnell lassen sich hierbei zwei Extreme erkennen, die das Spektrum der möglichen Verteilung von Namen auf Namensverwalter abgrenzen. Einerseits können sämtliche Namenseinträge für Kontexte und Objekte auf einem zentralen Namensverwalter plaziert werden, andererseits kann für jeden Namenseintrag ein separater Namensverwalter verantwortlich zeichnen (vgl. Abbildung 4.16).
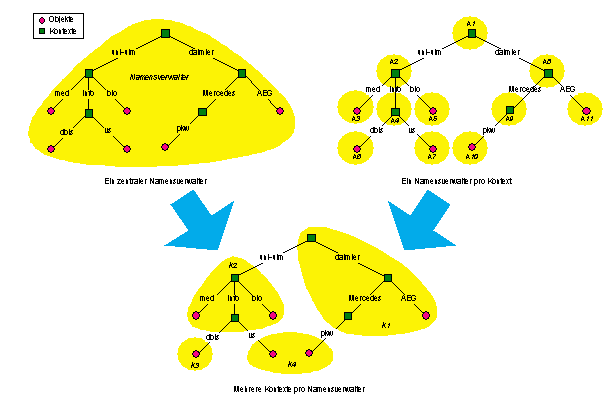
Abbildung 4.16: Verteilungsquanten von Namenseinträgen auf Namensverwalter
Die erst genannte Vorgehensweise entspricht einer zentralen Namensverwaltung. Da ein zentraler Namensverwalter jedoch in einem verteilten System sowohl bezüglich der Ausfallsicherheit als auch der Last ein kritisches Element darstellt, scheidet diese Option aus. Die Existenz einer zentralen Instanz repräsentiert einen eklatanten Widerspruch zur Definition eines verteilten Systems, die besagt, daß keine zentrale Komponente vorhanden sein darf, von der die Funktionsfähigkeit des Gesamtsystems abhängt.
Das andere Extrem stellt die Verwaltung einzelner Namen und Kontexte auf jeweils separaten Namensverwaltern (vgl. Abbildung 4.16) dar. Hierdurch kann eine breite Streuung der Last (Speicherbedarf, Rechenleistung) erreicht werden, allerdings entsteht ein hoher Kommunikationsaufwand für die Namensauflösung sowohl durch Navigation als auch durch vollständige Erkundung. Die breite Verteilung erfordert zusätzlich einen hohen Administrationsaufwand.
Im allgemeinen existieren sehr viel mehr benannte Objekte als Namensverwalter, so daß die oben aufgezeigte Verteilungsmethode nicht realisierbar ist. Das adäquate Verteilungsquantum wird sich daher in dem durch obige Lösungen abgesteckten Spektrum bewegen. Ein Namensverwalter administriert mehrere Kontext- und Namenseinträge, wobei mehrere Namensverwalter vorhanden sind. Dabei ist aus Gründen der Lastverteilung einerseits eine möglichst gleichförmige Verteilung der Einträge auf Namensverwalter anzustreben, andererseits ist, um eine hohe Effizienz des Gesamtsystems zu erreichen, eine Verteilung vorteilhaft, die den Zugriffsmustern auf die administrierten Namenseinträge entspricht. Das Zusammenfassen der Zuständigkeit für mehrere Kontexte auf einem Namensverwalter reduziert die Anzahl der zur Namensauflösung notwendigen Navigationsschritte.
A priori können jedoch nur selten exakte Aussagen über das Zugriffsverhalten von Klienten auf Namenseinträge gemacht werden. Sicher ist allerdings, daß Klienten häufig auf Einträge in ihrer physischen Nachbarschaft zugreifen, so daß es von Vorteil ist, wenn Namen physisch benachbarter Objekte auf benachbarten Namensverwaltern plaziert sind. Tragen Objekte jedoch logische Namen, die ortsunabhängig sind und sich nicht an organisatorischen oder physikalischen Strukturen orientieren, so ist dies jedoch i.d.R. nicht gewährleistet. Um die Präsenz von Namenseinträgen für lokale Objekte zu erreichen, wird daher auf Replikationsverfahren zurückgegriffen (vgl. Kapitel 5).
4.2.5 Aktive und passive Verteilungsverfahren
Grundsätzlich lassen sich Namen aktiv und passiv auf Namensverwalter verteilen. Bei der aktiven Verteilung von Namen wird der Namensverwalter, der einen neuen Namen für ein Objekt registriert, selbst aktiv und verteilt die dazugehörigen Namenseinträge an die übrigen Namensverwalter. Die aktive Verteilung neuer Namen in einem Kontext kann auch berücksichtigen, von welchem Namensverwalter ein Name in diesem Kontext bereits aufgelöst wurde. Ein neuer Name in diesem Kontext kann dann direkt in diesem Namensverwalter repliziert werden. Ein derartiges Vorgehen entspricht einer Rückwärtsverzeigerung von Namenseinträgen.[AL8]
Bei der passiven Verteilung von Namenseinträgen fordern interessierte Namensverwalter periodisch oder auf Anforderung Informationen über neue Einträge an. Der Namensverwalter, in dessen Zuständigkeitsbereich ein neuer Name für ein Objekt registriert wurde, bleibt zunächst inaktiv. Übergeordnete Namensverwalter können aber auch bestimmte Kontexte eines untergeordneten Namensverwalters „abonnieren“, so daß sie bei Änderungen in diesen Kontexten informiert werden. Ein Beispiel für die passive Verteilung geben verschiedene Suchdienste im Internet, die ihnen bekannte Server wiederholt kontaktieren, um Informationen über deren Inhalt zu sammeln, zu indizieren und für Suchanfragen zur Verfügung zu stellen.
Im folgenden wird lediglich die aktive Verteilung von Namenseinträgen betrachtet. Die passive Verteilung von Namenseinträgen könnte beispielsweise zur Aktualisierung vorgehaltener oder replizierter Namenseinträge auf Namensverwaltern Verwendung finden (vgl. Kapitel 5).
Die inhaltsgesteuerte Plazierung ermöglicht in hierarchischen Verwalternetzen die Verteilung logischer Namen unabhängig von ihrer physikalischen oder organisatorischen Zugehörigkeit.
4.3 Dynamische Verwaltung globaler Namensräume
In den vorangegangenen Abschnitten hat sich gezeigt, daß hierarchische Verwalterstrukturen, die dem Namensraum angepaßt sind, eine effiziente verteilte Namensverwaltung ermöglichen. Im folgenden wird daher vorausgesetzt, daß sowohl das Verwalternetz als auch der Namensraum hierarchisch organisiert sind. Übergeordnete Namensverwalter können somit Anfragen an für Namensraumsegmente zuständige, untergeordnete Namensverwalter delegieren und müssen selbst nur Namenseinträge mit den für die Weiterleitung von Anfragen notwendigen Navigationsinformationen administrieren.
Voraussetzung für die globale Auflösung von Namen durch Navigation im Verwalternetz ist die eindeutige Zuordnung von Namensraumsegmenten zu Namensverwaltern und die Existenz von Namenseinträgen mit Navigationsinformation für diese Namensraumsegmente. Bevor in diesem Kapitel Verfahren für die globale Namensauflösung durch Navigation und die Bereitstellung der für die Lokalisierung von Namenseinträgen im Verwalternetz erforderlichen Navigationsinformationen vorgestellt werden, müssen daher zunächst die Anforderungen an Namenseinträge und Navigationsinformationen in Namensverwaltern identifiziert werden.
4.3.1 Namenseinträge und Navigationsinformation in Namensverwaltern
Bereits in Kapitel 3 hat sich gezeigt, daß für die Navigation in hierarchischen Verwalternetzen die Konfigurationsinformation in Namensverwaltern ein zusammenhängendes hierarchisches Verwalternetz bilden und bestimmte Konsistenzbedingungen erfüllen muß. Weiter stellt sich die Frage, welche Navigationsinformation in Namensverwaltern notwendig ist und welche Bedingungen diese erfüllen muß, um Namenseinträge durch Navigation im Verwalternetz lokalisieren zu können. Zur Klärung dieser Frage betrachten wir die Verteilung eines simplen hierarchischen Namensraums auf hierarchisch organisierte Namensverwalter in Abbildung 4.17.
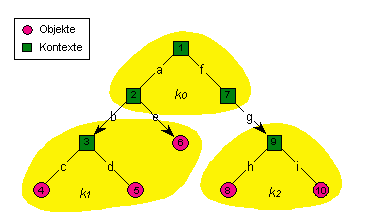
Abbildung 4.17: Verteilung eines Namensraums auf hierarchisch organisierte Namensverwalter
Jeder Namensverwalter in Abbildung 4.17 speichert in seiner Namensbasis Namenseinträge für Objekte und Kontexte, die er verwaltet. Diese Information reicht jedoch für die Auflösung globaler Namen durch Navigation noch nicht aus. Die in Abschnitt 4.3.2 vorgestellte Namensauflösung durch Navigation benötigt zusätzlich in den jeweiligen Namensverwaltern Navigationsinformation für Namensraumsegmente, die in lokalen Kontexten enthalten sind, jedoch selbst extern verwaltet werden. Diese Navigationsinformation zur Weiterleitung von Anfragen an andere Namensverwalter ist in Abbildung 4.17 durch Pfeile gekennzeichnet. Der Inhalt der Namensbasen der jeweiligen Namensverwalter aus Abbildung 4.17 wird in Tabelle 4.1 dargestellt.
|
Namensverwalter |
Namenseintrag |
Navigationsinformation |
Objekt-/Kontext-Bezeichner |
|
k0 |
/ |
|
|
|
k0 |
/a |
|
|
|
k0 |
/f |
|
|
|
k0 |
/a.b |
k1 |
|
|
k0 |
/a.e |
k1 |
|
|
k0 |
/f.g |
k2 |
|
|
k1 |
/a.b |
|
|
|
k1 |
/a.b.c |
|
|
|
k1 |
/a.b.d |
|
|
|
k1 |
/a.e |
|
|
|
k2 |
/f.g |
|
|
|
k2 |
/f.g.h |
|
|
|
k2 |
/f.g.i |
|
|
Tabelle 4.1: Namensbasen der Namensverwalter aus Abbildung 4.17
Die Bindung eines Namens an ein Objekt wird im sog. primären Namenseintrag festgehalten. Die Navigationsinformation, die direkt auf den primären Namenseintrag eines Namens verweist, hingegen ist im sog. administrativen Namenseintrag abgelegt. Diese Kopie des primären Namenseintrags, die vom administrativen Namensverwalter verwaltet wird, enthält jedoch nicht die eigentliche Namen-Objekt-Bindung, sondern lediglich Navigationsinformation, die direkt auf den primären Namenseintrag verweist. In Tabelle 4.1 wurden administrative Namenseinträge mit Navigationsinformation grau hinterlegt. Diese Einträge vermerken für den jeweiligen (partiellen) Namen eines externen Kontexts oder Objekts den Namensverwalter, der die zugehörigen primären Namenseinträge verwaltet.
Das Beispiel aus Abbildung 4.17 und der Inhalt von Tabelle 4.1 machen deutlich, daß Namenseinträge und die zugehörige Navigationsinformation in den Namensverwaltern bestimmte Bedingungen erfüllen müssen, um bei der globalen Auflösung von Namen durch Navigation die primären Namenseinträge im Verwalternetz lokalisieren zu können:
1. Eindeutigkeit der Bindung:
Jeder Name n ist an genau ein Objekt o oder einen Kontext y gebunden. Alle primären Namenseinträge, die denselben Namen n enthalten, benennen dasselbe Objekt o oder denselben Kontext y.
2. Existenz von Navigationsinformation:
a) Jeder Namensverwalter k muß Namenseinträge mit Navigationsinformation für Namen von Kontexten und Objekten besitzen, die in lokalen Kontexten enthalten sind, jedoch in externen Namensverwaltern k1,…,kj verwaltet werden.
b) Für jeden primären Namenseintrag in einem Namensverwalter k müssen im Verwalternetz Namenseinträge mit Navigationsinformation vorhanden sein, so daß er ausgehend von der Wurzel der Verwalterhierarchie k0 lokalisiert werden kann.
3. Eindeutigkeit der Navigationsinformation:
Da jeder Name n eines Kontexts y oder Objekts o in genau einem primären Namensverwalter k verwaltet wird, muß auch die Navigationsinformation und die Zuordnung von Namensraumsegmenten zu Namensverwaltern eindeutig sein (ohne Replikation und Partitionierung).
Obige drei Bedingungen sind notwendig und vollständig für die globale Namensauflösung durch Navigation. Weitere Bedingungen an die Informationen in Namensverwaltern sind nicht notwendig, erhöhen jedoch die Effizienz und die Ausfallsicherheit der Namensverwaltung:
4. Existenz übergeordneter Kontexte:
Falls zwei oder mehr Namen von Kontexten oder Objekten ein gemeinsames Präfix besitzen, so existiert in einem Namensverwalter k ein Namenseintrag für einen Kontext y, in dem diese Namen enthalten sind und der dieses Präfix zum Namen hat.
5. Majorisierung von Navigationsinformation:
Ist in Namensverwalter ki für einen Kontext y ein Namenseintrag mit Navigationsinformation vorhanden, die auf einen Namensverwalter kj verweist, so existiert in Namensverwalter ki kein Namenseintrag für einen Namen, der in Kontext y enthalten ist und dessen Navigationsinformation auf denselben Namensverwalter kj verweist.
6. Kenntnis der Bindung:
Jeder Kontext y und jedes Objekt o in einem Namensverwalter k muß seine(n) eigenen Namen n kennen, d.h. der primäre Namenseintrag sollte im selben Knoten wie das Objekt abgelegt sein. Zu jedem Namen n in Namensverwalter k muß festgestellt werden können, ob er ein Objekt oder einen Kontext bezeichnet.
Die Bedingungen zur Existenz übergeordneter Kontexte und zur Majorisierung beschränken die Namenseinträge mit Navigationsinformationen in Namensverwaltern auf die zur globalen Auflösung notwendigen Einträge. Die Kenntnis der Bindung gewährleistet, daß zu jedem Objekt oder Kontext lokal stets der vollständige globale Name vorhanden ist und somit der Name stets lokal aufgelöst werden kann (vgl. Abschnitt 4.3.4).
Die Konsistenz von Namenseinträgen und Navigationsinformationen wird durch Namensoperationen, wie dem Registrieren und dem Löschen von Namen beeinflußt. Nachdem die notwendigen Rahmenbedingungen in den Namensverwaltern identifiziert wurden, wird nun die globale Namensauflösung vorgestellt. Anschließend wird ein Verfahren zur globalen Registrierung von Namen hergeleitet, das die zur globalen Auflösung von Namen notwendige Navigationsinformation konsistent erzeugt und geeignet in Namensverwaltern plaziert.
4.3.2 Globale Auflösung hierarchischer Namen
Die bisher in Abschnitt 2.5 vorgestellten Methoden zur lokalen Namensauflösung bilden Namen innerhalb eines Namensverwalters in gegebenen Kontexten wiederum auf neue Namen und Kontexte oder Objekte ab. Dazu werden Namen syntaxgesteuert interpretiert und der lokale Namensgraph traversiert. Bei der globalen Auflösung von Namen wird zusätzlich anhand von Navigationsinformation im Verwalternetz navigiert. Die globale Auflösung von Namen besteht somit aus lokalen und knotenübergreifenden Operationen.
Die Funktion global resolve zur globalen Auflösung eines Namens n in einem gegebenen Kontext y beginnend in einem bestimmten Namensverwalter k wird nun wie folgt definiert:
![]()
Die globale Auflösung kennt ähnliche Zustände, wie die lokale Auflösung, liefert im Gegensatz zur lokalen Namensauflösung mittels resolve jedoch zusätzlich den Namensverwalter, in dem der primäre Namenseintrag des aufzulösenden Namens im Verwalternetz lokalisiert wurde. Die Menge der Zustände der globalen Namensauflösung SG enthält außerdem keine Zustände für das Traversieren von Bäumen (vgl. SL in Kapitel 2), sondern für die Navigation im hierarchischen Verwalternetz (prev node, next node).
Wie Abbildung 4.18 verdeutlicht, besteht die globale Namensauflösung aus einer Orientierungsphase und einer Navigationsphase. In der Orientierungsphase bewegt sich die Namensauflösung in der Verwalterhierarchie nach oben in Richtung Wurzel der Verwalterhierarchie, um in einem übergeordneten Namensverwalter einen Kontext zum aufzulösenden Namen zu ermitteln. Sobald ein Kontext ermittelt wurde, in dem der aufzulösende Name enthalten ist, beginnt die Navigationsphase, die den primären Namensverwalter des gesuchten Names mit Hilfe der Navigationsinformation in den Namenseinträgen übergeordneter Kontexte lokalisiert.
Erhält ein Namensverwalter eine Anfrage zur Auflösung eines globalen Namens, so wird, wie Abbildung 4.18 zeigt, zunächst versucht, den Namen lokal aufzulösen (Zustand: resolve). Gelingt dies (full match), so ist keine knotenübergreifende Auflösung notwendig.
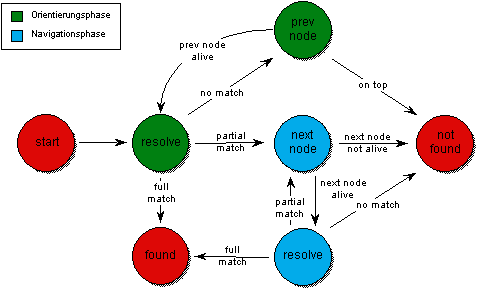
Abbildung 4.18: Zustände der globalen Namensauflösung
Bleibt die lokale Auflösung erfolglos (no match), so wendet sich der lokale Namensverwalter ki in der Orientierungsphase an den in der Hierarchie übergeordneten Namensverwalter ki-1 (Zustand: prev node), um mit dessen Hilfe den Namenseintrag des gesuchten Namens im Verwalternetz zu lokalisieren. Dieser Vorgang wird so lange wiederholt, bis ein Teil des Namens aufgelöst werden kann (partial match). Hat die Lokalisierung die Wurzel der Verwalterhierarchie k0 erreicht (on top), ohne daß ein Teil des Namens aufgelöst werden konnte, so terminiert die globale Namensauflösung ohne Erfolg (Zustand: not found).
Ist in der Namensbasis eines Namensverwalters ein Namenseintrag für einen Teil des aufzulösenden Namens enthalten (partial match), so beginnt die Navigationsphase. Der Name wird hier so weit wie möglich lokal interpretiert und die globale Auflösung bei demjenigen Namensverwalter fortgesetzt, auf den die Navigationsinformation im Namenseintrag mit der größten Übereinstimmung im Namen verweist (Zustand: next node). Die Lokalisierung des Namenseintrags zum gesuchten Namen wird sukzessive fortgesetzt, bis schließlich die Auflösung in demjenigen Namensverwalter terminiert, in dem der zugehörige primäre Namenseintrag vorhanden ist (Zustand: found), oder keine weiterführende Navigationsinformation mehr existiert (no match).
Um den in Abbildung 4.18 dargestellten Ablauf einer erfolgreichen globalen Namensauflösung zu verdeutlichen, sei nachfolgendes Beispiel gegeben. Ausgehend von Namensverwalter k6 (vgl. Abbildung 4.19) wird der globale Name „a.b.a“ aufgelöst. Da in k6 keine Übereinstimmung des aufzulösenden Namens mit vorhandenen Namenseinträgen besteht, wird die Namensauflösung zunächst im übergeordneten Namensverwalter k0 fortgesetzt. Hier befindet sich ein Namenseintrag mit Navigationsinformation für den Teilnamen „a.b“, so daß die Auflösung in Namensverwalter k5 fortgesetzt werden kann. Dieser leitet seinerseits die Auflösung zu k2, wo der administrative Namenseintrag zum gesuchten Namen plaziert wurde. Der administrative Namenseintrag enthält jedoch noch nicht die Namen-Objekt-Bindung, sondern verweist seinerseits auf den primären Namensverwalter k2 für den Namen „a.b.a“. Hier wird der primäre Namenseintrag für „a.b.a“ mit der Bindung an das Objekt ermittelt und schließlich an den initiierenden Namensverwalter k6 zurückgegeben.
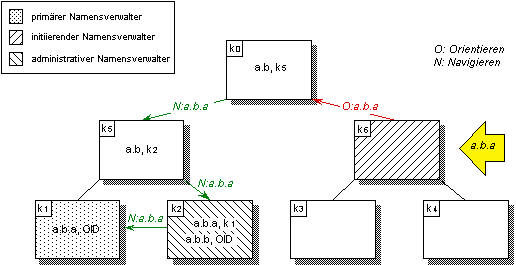
Abbildung 4.19: Globale Auflösung eines hierarchischen Namens durch Navigation
Ist ein generischer oder attributierter Name aufzulösen, so kann die Lokalisierung nicht bereits terminieren, sobald ein Namenseintrag ermittelt wurde. Notwendig ist dann die vollständige Erkundung des gesamten Verwalternetzes. Vom Zustand found wird dazu im Zustandsdiagramm aus Abbildung 4.18 die Lokalisierung so lange fortgesetzt, bis alle relevanten Teile des Verwalternetzes durchsucht sind und kein weiterer Eintrag mehr gefunden wird (vgl. hierzu Abschnitt 4.4.3.2).
Nach der Partitionierung des Verwalternetzes besteht generell die Gefahr, daß Kontexte über mehrere Namensverwalter verteilt und Namen von Objekten in verschiedenen Namensverwaltern repliziert sind. Solange der Zusammenhang des Verwalternetzes und die Funktionsfähigkeit der Namensverwalter gewährleistet ist, wird die Partitionierung von Kontexten durch die nachfolgend beschriebene syntaxgesteuerte Plazierung von Namenseinträgen in Namensverwaltern verhindert. Die Plazierung von Namenseinträgen bei Partitionierung des Verwalternetzes wird in Kapitel 5 beschrieben.
4.3.3 Globale Registrierung und Verteilung hierarchischer Namen
Die Registrierung globaler Namen hat zur Aufgabe, die zur Lokalisierung des primären Namensverwalters für einen Namen notwendigen Namenseinträge mit Navigationsinformation zu generierten und diese im Verwalternetz in ausgewählten Namensverwaltern zu plazieren. Hierbei sind zum einen die in Abschnitt 4.2.1 aufgestellten Kriterien zur Beurteilung der Güte der Verteilung von Namenseinträgen und zum anderen die Konsistenzbedingungen für Namenseinträge und Navigationsinformationen aus Abschnitt 4.3.1 zu berücksichtigen. Zusätzlich werden für die globale Verwaltung hierarchischer Namen folgende grundlegende Annahmen getroffen:
1. Namen von Kontexten ändern sich selten.
2. Objekte und ihre Namen sind in der Regel einer höheren Variabilität unterworfen.
3. Räumlich benachbart gespeicherte Objekte tragen häufig ähnliche Namen.
4. Objekte werden bevorzugt von räumlich benachbarten Instanzen zugegriffen.
Unter Berücksichtigung obiger Annahmen können Namenseinträge für Kontexte daher einen hohen Verteilungsgrad im Verwalternetz aufweisen und zur Steigerung der Verfügbarkeit repliziert und vorgehalten werden. Namenseinträge für Objekte hingegen werden zunächst nur lokal im primären Namensverwalter gehalten, in dem der Name für das Objekt registriert wurde. Namenseinträge mit Navigationsinformation zur Lokalisierung primärer Namenseinträge für Objekte werden nur verteilt, falls keine Namenseinträge übergeordneter Kontexte mit Navigationsinformation vorhanden sind, die zum primären Namenseintrag mit der Namen-Objekt-Bindung führen. Namenseinträge für ähnliche Namen werden in benachbarten Namensverwaltern plaziert, so daß eine Zusammenfassung von Namen zu Kontexten möglich wird. Da Objekte bevorzugt von räumlich benachbarten Instanzen zugegriffen werden, sollten die zugehörigen Namenseinträge in Namensverwaltern plaziert werden, die sich im selben Teil des Verwalternetzes befinden, wie der Objektverwalter.
Im folgenden Abschnitt wird die Plazierung von Namenseinträgen mit Navigationsinformation im Verwalternetz und die Erzeugung von Kontexten in Namensverwaltern eingehend diskutiert.
4.3.3.1 Syntaxgesteuerte Plazierung von Navigationsinformation
Voraussetzung zur Auflösung globaler Namen durch Navigation im Verwalternetz sind die in Abschnitt 4.3.1 aufgezeigten Bedingungen für Namenseinträge und Navigationsinformationen in Namensverwaltern. Um diese zu erfüllen, werden bei der Registrierung neuer Namen Namenseinträge mit Navigationsinformation syntaxgesteuert in Namensverwaltern zusammen mit Namenseinträgen übergeordneter Kontexte oder ähnlicher Namen (related)[4] plaziert.
Die syntaxgesteuerte Plazierung von Namenseinträgen gleicht weitgehend der Lokalisierung von Namenseinträgen bei der globalen Auflösung von Namen und besteht ähnlich wie die Lokalisierung von Namenseinträgen im Verwalternetz aus einer Orientierungs- und einer Navigationsphase, hier als Plazierungsphase bezeichnet. Bei der Plazierung von Namenseinträgen im Verwalternetz werden jedoch auch ähnliche Namen berücksichtigt. Dadurch werden Einträge so gruppiert, daß Namensverwalter auf den oberen Ebenen der Verwalterhierarchie entlastet und Partitionen des Namensraums vermieden werden.
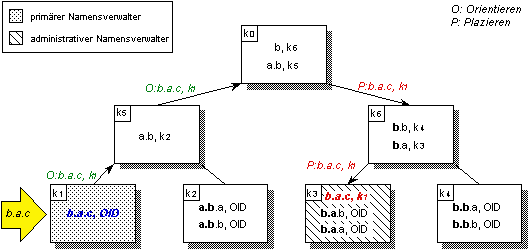
Abbildung 4.20: Orientierungs- und Plazierungsphase der syntaxgesteuerten Plazierung von Namen
Bei der Registrierung von Namenseinträgen werden primäre und administrative Namensverwalter unterschieden. Der primäre Namensverwalter für einen Namen ist derjenige Namensverwalter, in dem der Name von der Anwendung für ein Objekt registriert wurde. Hier befindet sich in der Regel auch das benannte Objekt. Der Namenseintrag im primären Namensverwalter enthält die Namen-Objekt-Bindung. Um diesen primären Namenseintrag im Verwalternetz lokalisieren zu können, existieren für den Namen im Verwalternetz weitere Namenseinträge mit Navigationsinformation, die auf den primären Namensverwalter verweisen. Dieser administrative Namenseintrag wird syntaxgesteuert im sog. administrativen Namensverwalter plaziert.
Das Beispiel in Abbildung 4.20 zeigt die syntaxgesteuerte Plazierung eines Namenseintrags in einer Hierarchie von Namensverwaltern. Der kursiv dargestellte Name „b.a.c“ wird im primären Namensverwalter k1 erzeugt und wandert zunächst in der Orientierungsphase die Verwalterhierarchie nach oben, ohne auf einen Kontext zu treffen, in dem er enthalten ist. In der Wurzel der Verwalterhierarchie k0 wird schließlich eine Übereinstimmung des ersten Teils des Namens mit dem Eintrag (b, k6) festgestellt. Der Name wandert nun in der Plazierungsphase zu Namensverwalter k6, auf den die Navigationsinformation in diesem Eintrag verweist. Dort findet sich ein Eintrag (b.a, k3), der eine weitergehende Übereinstimmung mit dem zu plazierenden Namen aufweist. Schließlich gelangt der Namenseintrag zu Namensverwalter k3, wo er schließlich plaziert wird, da kein Namenseintrag mit weiterführender Navigationsinformation mehr vorhanden ist. Als administrativer Namensverwalter für den Namen „b.a.c“ wurde damit k3 ermittelt. Hier wird ein Namenseintrag mit Navigationsinformation für den Namen „b.a.c“ plaziert, die auf den primären Namensverwalter k1 verweist.
Bevor das detaillierte Verfahren zur syntaxgesteuerten Plazierung von Namen in der Verwalterhierarchie vorgestellt wird, ist eine Begriffsbildung vorzunehmen. Hierzu sei n der Name eines Kontextes y oder Objektes o und N(k) die Namensbasis des Namensverwalters k.
· kprim(n) bezeichnet den primären Namensverwalter, in dem der primäre Namenseintrag für den Namen n mit der Namen-Objekt-Bindung bei der Registrierung oder Substitution erzeugt wurde.
· kadmin(n) bezeichnet den administrativen Namensverwalter, in dem der administrative Namenseintrag für den Namen n abgelegt ist, dessen Navigationsinformation direkt auf den primären Namensverwalter kprim(n) verweist.
· kref(n, k) ist derjenige Namensverwalter, auf den die Navigationsinformation im Namenseintrag für den Namen n in Namensverwalter k verweist.
· path(n):= k0,…,kprim(n) bezeichnet die Folge der Namensverwalter auf dem Pfad vom primären Namensverwalter kprim(n) des Namens n zur Wurzel der Verwalterhierarchie k0.
· Ein Name np heißt partieller Name von n, wenn np im Namensraum einen übergeordneten Kontext yj-1 für den Namen n eines Kontexts yj oder eines Objekts o bezeichnet. Der partielle Name np ist ganz in n enthalten und bezeichnet ein Präfix von n.
· npmax heißt maximaler partieller Name von n in Namensverwalter k, wenn npmax ein partieller Name von n ist und kein gemeinsamer partieller Name np von n und einem bel. Namen m aus N(k) existiert, so daß npmax partieller Name von np ist. Beispiel: Der maximale partielle Name für den Namen n:=„a.b.c.d“ in der Namensbasis N(k):={„a.b.c.e“, „a.b.f“} im Namensverwalter k ist npmax:= „a.b.c“.
Nachdem die notwendigen Begriffe definiert sind, wenden wir uns der syntaxgesteuerten Plazierung von Namen zu.
Orientierungsphase:
In der Orientierungsphase wird ausgehend vom primären Namensverwalter ki:=kprim(n), in dem der zu registrierende Name n eines Objekts oder Kontextes erzeugt wurde und der primäre Namenseintrag für n abgelegt werden soll, versucht auf dem Weg zur Wurzel der Verwalterhierarchie einen Namensverwalter kj zu ermitteln, der einen Kontext verwaltet, in dem der neue Name enthalten ist.
Dazu wird ein zu registrierender Name n von einem Namensverwalter ki so lange nach oben zum jeweils übergeordneten Namensverwalter ki-1 weitergegeben, bis
1. Fall: in einem Namensverwalter kj ein Namenseintrag für einen partiellen Namen np von n ermittelt wird, der einen Kontext bezeichnet, in dem der gesuchte Name n enthalten ist (np ist Präfix von n). Bezeichnet der partielle Name np ein Objekt, so terminiert die Registrierung, da ein gleichnamiger Kontext nicht mehr registriert werden kann.
2. Fall: in einem Namensverwalter kj ein Namenseintrag für einen Namen m eines Objekts oder Kontextes ermittelt wird, zu dem der zu registrierende Name n einen partiellen Namen darstellt (n ist Präfix von m). Stimmt die Navigationsinformation kref(m, kj) im Namenseintrag von m mit der des Namenseintrags von n überein kref(m, kj)= kref(n, kj):=ki, so terminiert die Orientierungsphase, andernfalls wird sie fortgesetzt. Bezeichnet der zu registrierende Name n ein Objekt, so terminiert die Registrierung, da ein gleichnamiger Kontext entstehen kann.
3. Fall: in einem Namensverwalter kj ein Namenseintrag für einen Namen m ermittelt wird, der dem zu registrierenden Namen n entspricht.
4. Fall: die Wurzel der Verwalterhierarchie erreicht wird (kj:=k0).
Ist eine dieser Bedingungen erfüllt, so beginnt die Plazierungsphase. In der Orientierungsphase wird zudem für jeden zu plazierenden Namenseintrag der Pfad path(n):= k0,…,kprim(n) vom primären Namensverwalter kprim(n) zur Wurzel der Verwalterhierarchie k0 vermerkt. Kann der übergeordnete Namensverwalter ki-1 nicht erreicht werden, so terminiert die Registrierung mit einem Fehlerzustand.
Plazierungsphase:
In der Plazierungsphase wird versucht, durch Navigation im Verwalternetz einen geeigneten administrativen Namensverwalter für den neuen Namenseintrag zu ermitteln. Dazu werden die Navigationsinformationen in Namenseinträgen für übergeordnete Kontexte und ähnliche Namen genutzt.
Jeder Navigationsschritt der Plazierungsphase reduziert ausgehend von k0 den in der Orientierungsphase gebildeten Pfad path(n):= k0,…,kprim(n) jeweils um einen Namensverwalter. Enthält der Pfad nach der Navigation in der Plazierungsphase noch Namensverwalter, so kann die Plazierung des Namenseintrags im Verwalternetz entlang des restlichen Pfades weiter verbessert werden. Dazu wird in den Namensverwaltern des restlichen Pfades jeweils ein Namenseintrag für n mit Navigationsinformation auf den nächsten Namensverwalter auf dem Pfad registriert.
Falls zu n kein maximaler partieller Name npmax im Verwalternetz ermittelt werden kann, wird ein Namenseintrag für n im obersten Namensverwalter k0 registriert und in allen Namensverwaltern entlang des Pfads path(n):= k0,…,kprim(n) zum primären Namensverwalter kprim(n) aufgenommen. Namenseinträge, die nicht plaziert und mit anderen Namen zu Kontexten zusammengefaßt werden können, sammeln sich so in der Wurzel der Verwalterhierarchie an (vgl. Abbildung 4.21).

Abbildung 4.21: Propagieren von Navigationsinformation auf dem Pfad zum primären Namensverwalter
In der Plazierungsphase werden sieben Fälle unterschieden, je nachdem, welche Beziehungen zwischen den Namenseinträgen des in der Orientierungsphase ermittelten Namensverwalters kj und dem zu registrierenden Namen n bestehen:
1. Fall: Die Orientierungsphase endete in der Wurzel der Verwalterhierarchie (kj=k0). Existiert in k0 kein maximaler partieller Name npmax für den Namen n, so wird ausgehend von der Wurzel der Verwalterhierarchie ki:=k0 in jedem Namensverwalter auf dem Pfad path(n):= k0,…,kprim(n) zum primären Namensverwalter kprim(n) jeweils ein Namenseintrag für n angelegt, dessen Navigationsinformation jeweils auf den nächsten Namensverwalter ki+1 auf dem Pfad path(n):= k0,…,kprim(n) verweist. Schließlich wird ein Namenseintrag mit der Namen-Objekt-Bindung für n in die Namensbasis des primären Namensverwalters kprim(n) aufgenommen.
2. Fall: Wurde in einem Namensverwalter kj ein Namenseintrag für einen partiellen Namen np von n ermittelt, so wandert der Namenseintrag für den zu registrierenden Namen n zu demjenigen Namensverwalter kref(np, kj), auf den die Navigationsinformation des Namenseintrags für np verweist. Die Plazierungsphase wird mit kj:=kref(np, kj) fortgesetzt.
3. Fall: Wurde in einem Namensverwalter kj ein Namenseintrag ermittelt, zu dessen Name m der zu registrierende Name n einen partiellen Namen darstellt (n ist Präfix von m) und dessen Navigationsinformation mit der des Namenseintrags für n übereinstimmt (kref(m, kj)=kref(n, kj):=ki) dann wird in der Kontextbildungsphase der Eintrag für m durch den Eintrag für n ersetzt und das Verfahren beginnt erneut mit der Orientierungsphase, wobei ki:=kj (Majorisierung).
4. Fall: Sind in einem Namensverwalter kj Namenseinträge für Namen vorhanden, die ein gemeinsames Präfix mit n besitzen, so wird der zu registrierende Name n an denjenigen Namensverwalter weitergegeben, auf den die Navigationsinformation des Namenseintrags verweist, dessen Name m den maximalen partiellen Namen npmax zu n in kj ergibt, sofern die Navigationsinformation im Namenseintrag für m nicht auf den primären Namensverwalter kprim(m) verweist, d.h. kref(m, kj)¹ kprim(m).
5. Fall: Ist der zu registrierende Name n mit dem Namen m eines Namenseintrags in Namensverwalter kj identisch (n=m), so beginnt die Kontextbildungsphase. Hierbei ist in der Kontextbildungsphase noch zu unterscheiden, ob die betrachteten Namen Objekte oder Kontexte bezeichnen.
6. Fall: Der Namenseintrag kann durch Navigation (Fall 2 und 4) in kj nicht weiter plaziert werden, im Pfad path(n):= k0,…,kprim(n) von der Wurzel der Verwalterhierarchie k0 zum primären Namensverwalter kprim(n) sind jedoch noch Namensverwalter verzeichnet. Dann wird ausgehend von kj in den Namensverwaltern auf dem restlichen Pfad path(n):= kj,…,kprim(n) zum primären Namensverwalter kprim(n) jeweils ein Namenseintrag für n mit Navigationsinformation kref(n, kj):=ki+1 auf den jeweils nächsten Namensverwalter auf dem Pfad plaziert, solange eine Verbesserung der Plazierung im Verwalternetz möglich ist.
7. Fall: Ist in Namensverwalter kj ein administrativer Namenseintrag für einen Namen m vorhanden, der ein gemeinsames Präfix mit n besitzt, dessen Navigationsinformation jedoch auf den primären Namensverwalter kprim(m) verweist, so wird in den Namensverwaltern auf dem Pfad path(n):= kj,…,kprim(n) jeweils ein Namenseintrag für m mit Navigationsinformation auf den nächsten Namensverwalter auf dem Pfad plaziert, solange eine Verbesserung der Plazierung im Verwalternetz möglich ist.
Die Plazierungsphase wird mit ki:=kref(m, kj) so lange wiederholt, bis
· ein Blatt der Verwalterhierarchie erreicht ist. In diesem Namensverwalter kj beginnt dann die Kontextbildungsphase.
· keine Verbesserung der Plazierung des Namenseintrags durch Navigation mehr erzielt werden kann, da:
1. kein Namenseintrag mit weiterführender Navigationsinformation in kj vorhanden ist.
2. die Navigationsinformation eines ähnlichen Namenseintrags auf den primären Namensverwalter kprim(m) verweist.
3. die Länge des Pfades k0,…,kj von der Wurzel der Verwalterhierarchie zum ermittelten Namensverwalter kj der Anzahl der Namensteile des hierarchischen Namens entspricht.
Der in der Plazierungsphase ermittelte Namensverwalter kj entspricht dem administrativen Namensverwalter kadmin(n), in dem der administrative Namenseintrag mit Navigationsinformation auf den primären Namensverwalter abgelegt wird.
Die soeben vorgestellten beiden Phasen der syntaxgesteuerten Plazierung gewährleisten, daß globale Namenseinträge immer zusammen mit ähnlichen Einträgen im Verwalternetz plaziert werden und die Einträge in den Namensverwaltern stets die größtmögliche Übereinstimmung zeigen. Ungeklärt ist bisher noch die Frage, wie in Namensverwaltern neue Kontexte erzeugt werden und wie im ermittelten administrativen Namensverwalter kadmin(n):=kj die plazierten Namenseinträge weiter behandelt werden. Dieser Frage wendet sich der nächste Abschnitt zu.
4.3.3.2 Generierung globaler Kontext-Einträge
Nachdem in der Orientierungs- und der Plazierungsphase der administrative Namensverwalter kj ermittelt wurde, in dem der administrative Namenseintrag für den neu zu registrierenden Namen n zu plazieren ist, wird nun unter den Namenseinträgen in kj ein maximaler partieller Name npmax zu n ermittelt. npmax bezeichnet dann einen gemeinsamen Kontext von n mit vorhandenen Namen, der seinerseits zur Registrierung an übergeordnete Namensverwalter weitergeben wird, falls er nicht bereits in der Namensbasis von kj vorhanden ist. Hinzukommende Namenseinträge für übergeordnete Kontexte substituieren vorhandene Namenseinträge für untergeordnete Kontexte (Majorisierung), die auf denselben Namensverwalter verweisen (vgl. Abbildung 4.22). Dazu wird der neu generierte Namenseintrag für npmax mit Navigationsinformation auf den Namensverwalter kj im Verwalternetz plaziert.
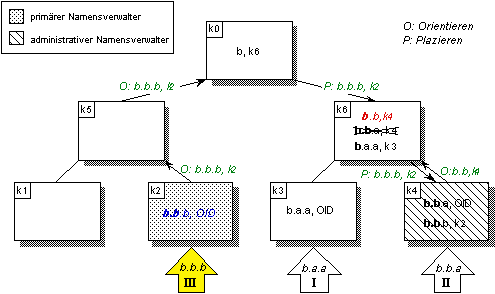
Abbildung 4.22: Substituieren von Namenseinträgen durch Einträge übergeordneter Kontexte
Das Beispiel in Abbildung 4.22 zeigt den Inhalt der Namensbasen der Namensverwalter, nachdem im ersten (I) und zweiten Schritt (II) die Namen „b.a.a“ und „b.b.a“ registriert wurden. Wird in obigem Beispiel in einem dritten Schritt (III) zusätzlich der Name „b.b.b“ registriert, so wird der Namenseintrag für den Namen „b.b.a“ durch den Namenseintrag des Kontexts „b.b“ substituiert.
Sind in der Verwalterhierarchie nicht alle Namensverwalter permanent erreichbar, so kann bei diesem Verfahren derselbe Kontext mehrfach gebildet werden. Dadurch entstehen Partitionen des Namensraums, die dieselben Kontexte enthalten. Das hat zur Folge, daß die Lokalisierung von Namenseinträgen aufwendiger wird, da die Eindeutigkeit der Navigationsinformation nicht mehr gewährleistet ist. Verfahren, um die Partitionierung von Kontexten zu vermeiden, werden in Kapitel 5 vorgestellt.
Das rekursive Verfahren zur Generierung neuer Kontexte im administrativen Namensverwalter kj, der in der Plazierungsphase ermittelt wurde, stellt sich wie folgt dar:
Kontextbildungsphase:
Die Kontextbildungsphase ermittelt in der Namensbasis N(kj) des in der Plazierungsphase ermittelten administrativen Namensverwalters kj einen maximalen partiellen Namen npmax zu n. Dieser ist der Name eines neuen Kontexts, der seinerseits im Verwalternetz global registriert wird. Bei der Bildung von Kontexten werden folgende Fälle unterschieden:
1. Fall: Wurde ein maximaler partieller Name npmax ermittelt, und entspricht dieser weder n noch einem Namen m in N(kj), dann wird n in die Namensbasis von kj aufgenommen und der Teilname npmax in der Namensverwaltung neu registriert (entspricht dem Zustand: create context in Abbildung 4.23). Das Verfahren beginnt mit ki:=kj und n:=npmax von neuem mit der Orientierungsphase. Die Navigationsinformation kref(n, kj):=kl des Namenseintrags für n in N(kj) wird so gesetzt, daß sie auf den nächsten Namensverwalter kl auf dem restlichen Pfad kl,…,kprim(n) verweist.
2. Fall: Befindet sich in N(kj) ein Name m, zu dem n ein partieller Name ist, so wird, falls kref(m, kj)=kref(n, kj):=ki, der Namenseintrag für m in der Namensbasis von kj durch einen Namenseintrag für n substituiert (entspricht dem Zustand: substitute in Abbildung 4.23). Das Verfahren beginnt mit n und ki:=kj von neuem mit der Orientierungsphase.
3. Fall: n ist identisch mit einem Namen m in N(kj):
Gilt kref(m, kj)=kref(n, kj):=ki, so wird der neue Eintrag n verworfen. Andernfalls wird der Name eines Kontexts registriert, falls es sich um denselben Kontext handelt, der Name eines Objekts jedoch wird als Duplikat zurückgewiesen. Die Auflösung terminiert in allen drei Fällen.
Wird ein neuer Eintrag für den Namen npmax durch Kontextbildung erzeugt, so erhält er als primären Namensverwalter kprim(npmax,) den Namensverwalter kj, auf dem der Eintrag generiert wurde (kprim(npmax,):=kj). Neue Namenseinträge für Kontexte werden ihrerseits wieder syntaxgesteuert im Verwalternetz plaziert.
Die Übergänge zwischen den verschiedenen Phasen der Registrierung von Namenseinträgen zeigt Abbildung 4.23.
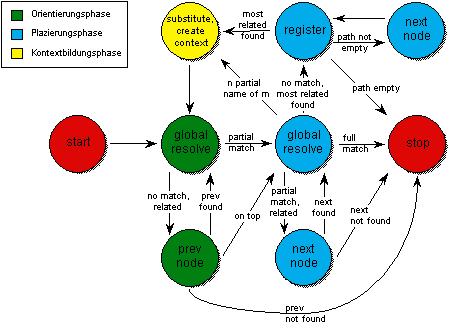
Abbildung 4.23: Zustände und Übergänge bei der globalen Registrierung von Namen
Das soeben vorgestellte Verfahren führt zu einer zunehmenden Verallgemeinerung der Navigationsinformation in den Namensverwaltern der Hierarchie von unten nach oben. Beim Löschen von Objekt-Namen hingegen findet wieder eine Konkretisierung der Navigationsinformation statt.
4.3.4 Umkehrung der globalen Namensauflösung
Der primäre Zweck einer Namensverwaltung besteht in der Abbildung von Namen auf Objekt-Bezeichner, die den Zugriff auf die spezifizierten Objekte erlauben. In bestimmten Ausnahmesituation ist es jedoch erforderlich, ausgehend vom Objekt-Bezeichner auf den globalen Namen eines Objekts zu schließen (vgl. Abschnitt 2.5).
![]()
Zur Realisierung einer globalen Abbildung von Objekt-Bezeichnern auf Namen gibt es verschiedene Möglichkeiten.
Besitzen die Objekt-Bezeichner eine Struktur, die zur Lokalisierung von Objektverwaltern im Netzwerk verwendet werden kann, und ist zusammen mit dem Objekt, wie in den in Abschnitt 4.3.1 aufgestellten Konsistenzbedingungen für Namenseinträge gefordert, im Objektverwalter auch der zugehörige Name abgelegt, so kann ausgehend vom Objekt-Bezeichner stets auf den Namen eines Objekts geschlossen werden. Ortsabhängige Objekt-Bezeichner besitzen allerdings den Nachteil, daß sie nicht migrationsinvariant sind.
Falls Objekt-Bezeichner keine Ortsinformation für die Lokalisierung des zugehörigen Namenseintrags enthalten, erscheint die Umkehrabbildung NameofObjekt zur globalen Namensauflösung global resolve auf den ersten Blick schwierig zu realisieren.
Eine Möglichkeit besteht darin, für die Umkehrabbildung ein globales Verzeichnis aller Objekt-Bezeichner zu verwalten, wie es für die Abbildung von IP-Adressen auf Domain-Namen im DNS verwendet wird. Ein separates Verzeichnis mit Objekt-Bezeichnern erfordert jedoch einen zusätzlichen Verwaltungsaufwand.
Durch die in Abschnitt 4.3.1 aufgestellten Konsistenzbedingungen und den Rückgriff auf vorgehaltene Namenseinträge (vgl. Kapitel 5) wird es jedoch möglich, die Umkehrabbildung zur globalen Namensauflösung auch ohne ein separates Verzeichnis zu realisieren. Nach den Konsistenzbedingungen für Namenseinträge sollte der primäre Namenseintrag bei der Benennung eines Objekts stets in der Namensbasis des Objektverwalters abgelegt werden. Ändern Objekte ihre Lokation, so hat der Objektverwalter dafür Sorge zu tragen, daß auch der primäre Namenseintrag zu dieser Lokation migriert und die zugehörige Navigationsinformation im administrativen Namensverwalter wieder auf den primären Namensverwalter mit dem primären Namenseintrag verweist. Wird beim Objektzugriff eine Kopie des Objekts erstellt, so sollte nach den Konsistenzbedingungen aus Abschnitt 4.3.1 auch der replizierende Rechner den zugehörigen Namenseintrag als Kopie enthalten. Ferner wird zugrundegelegt, daß der erstmalige Zugriff auf ein Objekt nur über den Namen erfolgt. Der zugehörige Namenseintrag zum aufgelösten Namen wird dabei lokal vorgehalten, um wiederholte Anfragen zu beschleunigen. Die Zuordnung von Objekt-Bezeichner zum Namen liegt beim Objektzugriff somit lokal vor und die Umkehrabbildung kann durch die lokalen Verfahren der Namensverwaltung realisiert werden (vgl. Abschnitt 2.5).[AL9]
4.3.5 Löschen globaler Namenseinträge
Wesentliche Eigenschaft einer dynamischen Namensverwaltung ist es, daß Namen nicht nur registriert, sondern auch wieder aus dem Namensraum entfernt werden können. Das Löschen von Namen im globalen Namensraum ist die direkte Umkehrung des zuvor beschriebenen Vorgangs der Registrierung globaler Namen. Werden Namenseinträge aus den Namensbasen von Namensverwaltern entfernt, so führt dies in der dynamischen globalen Namensverwaltung zur Konkretisierung der Navigationsinformation im Verwalternetz.
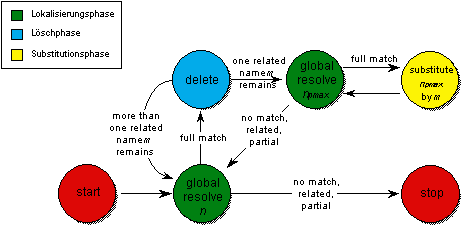
Abbildung 4.24: Zustände beim Löschen globaler Namenseinträge
Soll eine Bindung von Name zu Objekt-Bezeichner aus dem globalen Namensraum entfernt werden, so werden in der Lokalisierungsphase des Löschvorgangs alle Namenseinträge für den zu löschenden Namen n im Verwalternetz ermittelt (vgl. Abbildung 4.24). Die Navigationsinformation im Namenseintrag des administrativen Namensverwalters verweist auf den primären Namensverwalter, aus dessen Namensbasis der Namenseintrag ebenfalls zu entfernen ist.
Existiert in einem Namensverwalter ein Namenseintrag für den zu löschenden Namen n (full match), so beginnt die Löschphase und der Namenseintrag wird aus der Namensbasis des zuständigen Namensverwalters entfernt. Sind im selben Namensverwalter mehrere ähnliche Namenseinträge (more than one related name remains) präsent, d.h. der übergeordnete Kontext enthält mehr als einen weiteren Namenseintrag, so wird versucht, weitere Namenseinträge für den zu löschenden Namen im Verwalternetz zu lokalisieren und zu löschen. Der Löschvorgang ist beendet, sobald keine passenden Namenseinträge mehr vorhanden sind. Ist nach dem Löschen eines Namenseintrags nur noch ein einziger Name m im übergeordneten Kontext (mit dem Namen npmax) vorhanden (one related name remains), so werden die Namenseinträge für diesen Kontext lokalisiert und durch Namenseinträge für m ersetzt. Der Vorgang wird wiederholt, bis kein Namenseintrag für den Kontext mehr vorhanden ist. In letzterem Falle wird der Kontext obsolet und muß entfernt werden.
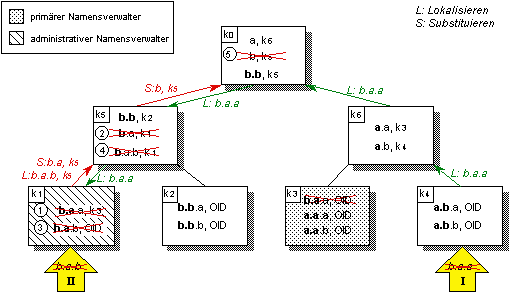
Abbildung 4.25: Beispiel für das Löschen globaler Namen
Der Vorgang des Löschens soll nun kurz an einem Beispiel verdeutlicht werden. Erhält ein Namensverwalter k4 im System den Auftrag (I), den Namen „b.a.a“ zu löschen, so wandert der Löschauftrag im Beispiel aus Abbildung 4.25 zum administrativen Namensverwalter k1, der den administrativen Namenseintrag für „b.a.a“ enthält. Hier wird der Eintrag für „b.a.a“ entfernt ( Schritt ¿ in Abbildung 4.25). Da im übergeordneten Kontext namens „b.a“ lediglich der Eintrag für den Namen „b.a.b“ verbleibt, wird dieser zur Substitution an k5 geleitet, um den Eintrag für „b.a“ durch „b.a.b“ zu ersetzen (Schritt ≠). Der Löschvorgang terminiert, da im übergeordneten Kontext namens „b“ ein weiterer Name „b.b“ enthalten ist. Der administrative Namensverwalter k1 kontaktiert anschließend den primären Namensverwalter k3, um den Eintrag auch hier zu entfernen.
Soll nun zu einem späteren Zeitpunkt (II) auch der Eintrag „b.a.b“ entfernt werden, so muß nach dem Löschen von „b.a.b“ in k1 (Schritt ¬) auch der Namenseintrag für „b.a.b“ mit Navigationsinformation auf k1 im Namensverwalter k5 entfernt werden (Schritt √). Da nach dem Löschen von „b.a.b“ in k5 der Eintrag „b.b“ als einziger im übergeordneten Kontext „b“ verbleibt, wird dieser anschließend in k0 durch „b.b“ substituiert (Schritt ƒ). Hier endet der Löschvorgang schließlich, da keine weiteren Namenseinträge für „b.a.b“ und „b“ mehr im Verwalternetz vorhanden sind.[AL10]
Die dynamische globale Namensverwaltung plaziert Namenseinträge mit Navigationsinformation für die Lokalisierung des primären Namenseintrags syntaxgesteuert im Verwalternetz. Die Bildung von Kontexten reduziert dabei die Anzahl der notwendigen Namenseinträge erheblich.
4.4 Globale Verwaltung generischer, synonymer und attributierter Namen
In den vorangegangenen Abschnitten wurde die globale Verwaltung hierarchischer Namen behandelt. Die nachfolgende Anschnitt greift nun die Problematik der Verwaltung synonymer und attributierter Namen und der eng damit verbundenen Behandlung generischer Anfragen auf.
4.4.1 Verwaltung synonymer Namen
Benutzer eines Rechnersystems haben das Bedürfnis, ihre Arbeitsumgebung individuell zu gestalten. Diese soll eine subjektive Sicht auf die vorhandenen Informationen bieten. Um die Komplexität der Arbeitsumgebung für den Benutzer zu reduzieren, sollen ferner nur die für den Benutzer relevanten Informationen dargestellt werden. Die dynamische globale Namensverwaltung unterstützt die Individualisierung der Benutzerumgebung, indem sie synonyme Namen zur Verfügung stellt, mit deren Hilfe individuelle Sichten des globalen Namensraums erzeugt werden können.
Vorteilhaft haben sich in diesem Zusammenhang sogenannte Aliases, kurze einprägsame Namen, die Verweise auf den eigentlichen Namen eines Objekts darstellen, erwiesen (vgl. auch Abschnitt 2.4.4). Die Signifikanz dieser Art synonymer Namen bleibt i.d.R. auf den aktuellen Kontext beschränkt. Als Gültigkeitsbereich für Synonyme können aber auch bestimmte Kontexte, der lokale Knoten, der Rechnerverbund und der globale Bereich dienen.
Durch die Existenz von Synonymen stellt die Abbildung von Namen auf Objekt-Bezeichner nun keine bijektive Funktion mehr dar. Da für ein Objekt mehrere äquivalente Namen existieren können, müssen im folgenden auch Beziehungen zwischen synonymen Namen in Betracht gezogen werden, die über den gemeinsamen Objekt-Bezeichner, an den sie gebunden sind, hergestellt werden.
4.4.1.1 Repräsentation von Synonymen im Namensraum
Synonyme Namen sind über einen gemeinsamen Objekt-Bezeichner an dasselbe Objekt gebunden (vgl. Abbildung 4.26). Hierbei trifft die dynamische globale Namensverwaltung jedoch keine Unterscheidung zwischen primären und sekundären Namen.

Abbildung 4.26: Zuordnung von Synonymen über gemeinsame Objekt-Bezeichner in der Namensdatenbank
Die Zuordnung von Synonymen zu einem Namen innerhalb eines Namensverwalters kann über den Suchbaum der Objekt-Bezeichner (vgl. hierzu Anhang C) hergestellt werden und stellt somit keine besondere Schwierigkeit dar (vgl. Abbildung 4.26). Hier ist zu jedem Objekt-Bezeichner vermerkt, in welchen Namenseinträgen er enthalten ist.
Aufwendiger ist es jedoch, global eine Beziehung zwischen synonymen Namen über den Objekt-Bezeichner herzustellen. Diese Aufgabe entspricht der Ermittlung aller Namen zu einem gegebenen Objekt-Bezeichner (vgl. Abschnitt 4.3.4). Als Lösung bietet sich an, zusammen mit den Namen im primären Namensverwalter auch alle zugehörigen Synonyme abzulegen, so daß diese jederzeit lokal über den gemeinsamen Objekt-Bezeichner zugeordnet werden können.
Wie bereits in Abschnitt 2.3.3.4 gezeigt, kann die Darstellung synonymer Namen für Kontexte im globalen Namensraum entweder in azyklischen gerichteten Graphen oder in Baumstrukturen erfolgen (vgl. Abbildung 2.25). Letztere Methode hat den Nachteil, daß bei der Registrierung von Synonymen für gemeinsame Kontexte derselbe Bezeichner verwendet werden muß, um sie eindeutig identifizieren zu können. Erheblich einfacher ist die Repräsentation von Synonymen in azyklischen gerichteten Graphen. Hier ist lediglich der Bezeichner des gemeinsamen Kontexts zu ermitteln und für die Synonyme dieses Kontexts zu registrieren.
Betrachtet man beispielsweise die synonymen
Namen n1:= „a.b.c.d.e“ und n2:= „x.y.z.c.d.e“, so
besitzen diese einen gemeinsamen Namensteil „c.d.e“ im Kontext „a.b“ bzw.
„x.y.z“. Die Namen „a.b“ und „x.y.z“ sind Synonyme desselben Kontexts. Daher
muß lediglich der Teil des Namens n2
als Synonym registriert werden, der sich vom Namen n1 unterscheidet. Ein neuer Namenseintrag für den
gemeinsamen Namensteil „c.d.e“ muß nicht angelegt werden.[AL11]
4.4.1.2 Globale Verwaltung synonymer Namen
Der Existenz synonymer Namen müssen auch die Namensoperationen der dynamischen globalen Namensverwaltung Rechnung tragen. Die Namensoperation zum Ermitteln der zu einem gegebenen Namen n1 synonymen Namen {n2,…,nj} ist eine Erweiterung der aus Abschnitt 4.3.4 bekannten Umkehrfunktion zur globalen Namensauflösung. Hierzu sind folgende Schritte notwendig:
1. Zunächst wird für den Namen n1 der primäre Namensverwalter kprim(n1) lokalisiert.
2. Über den Objekt-Bezeichner o(n1) des Namens n1 werden im primären Namensverwalter kprim(n1) alle zu n1 synonymen Namen {n2,…,nj} ermittelt (vgl. hierzu Abschnitt 4.3.4).
3. Auch wenn zu Objekt-Bezeichner o(n1) nur der Namenseintrag zu n1 existiert, muß jeder Pfad zur Wurzel des Namensraums zurückverfolgt werden, da optionale Pfade synonyme Namen für Kontexte darstellen können (vgl. Abbildung 2.24).
Bei der Registrierung synonymer Namen zu einem gegebenen Namen sind diese auch im primären Namensverwalter des Namenseintrags zu plazieren. Hierzu sind folgende Schritte notwendig:
1. Bei der Registrierung eines synonymen Namens n2 zu einem existierenden Namen n1 wird zunächst der für den Namen n1 zuständige primäre Namensverwalter kprim(n1) lokalisiert und der Objekt-Bezeichner o(n1) für den Namen n1 ermittelt.
2. Im primären Namensverwalter kprim(n1) wird für den synonymen Namen n2 ein lokaler Namenseintrag mit dem Objekt-Bezeichner o(n1) angelegt.
3. Der synonyme Name n2 wird global registriert. Im für n2 zuständigen administrativen Namensverwalter wird ein Namenseintrag mit Navigationsinformation plaziert, die auf den primären Namensverwalter kprim(n1)=kprim(n2) verweist.
Besitzt der Name n1 zusammen mit dem synonymen Namen n2 einen gemeinsamen partiellen Namen np, dann teilen sich die Namen n1 und n2 einen gemeinsamen Kontext. In diesem Fall wird der Name n2|np als Synonym für den Namen des Kontexts n1|np registriert.
Unter Berücksichtigung der Existenz von Synonymen sind beim Löschen eines Objekts namens n1 im primären Namensverwalter kprim(n1) auch alle Synonyme {n2,…,nj} zu entfernen. Ebenso müssen die Namenseinträge mit Navigationsinformation für die synonymen Namen {n2,…,nj} in den zuständigen administrativen Namensverwaltern entfernt werden.[AL12]
4.4.2 Auflösung generischer Namensanfragen
Neben der Verwaltung von Synonymen erfordert in der dynamischen globalen Namensverwaltung die Auflösung generischer Namen besondere Aufmerksamkeit. Generische Namen zeichnen sich dadurch aus, daß in Namensanfragen Platzhalter (sog. Wildcards) enthalten sind.
Die Verwendung von Platzhaltern hat zur Konsequenz, daß die globale Namensauflösung alle Namenseinträge, die der gegebenen Beschreibung des Namens genügen, in verschiedenen Namensverwaltern lokalisieren muß. Im Gegensatz zur vollständig spezifizierten Namensanfrage ist daher jeder Pfad im Namensgraphen zu verfolgen, der den aufzulösenden generischen Namen repräsentieren könnte.
4.4.2.1 Lokale Auflösung generischer Namen
Im Normalfall terminiert die Auflösung von Namen, sobald ein adäquater Namenseintrag für einen Kontext oder ein Objekt ermittelt wurde (vgl. Zustandsdiagramm in Abbildung 4.18). Diese einfache Art der Namensauflösung von Namen findet beispielsweise im Domain Name System [Mockapetris, 88] Anwendung. Sie endet, sobald eine IP-Adresse ermittelt wurde, das gesamte Verzeichnis durchsucht oder eine bestimmte Zeitspanne verstrichen ist.
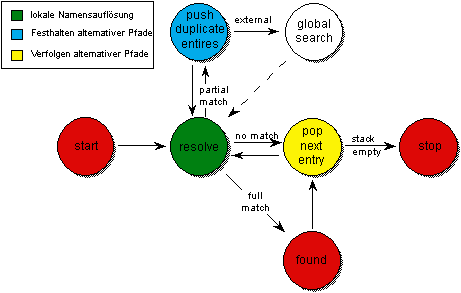
Abbildung 4.27: Zustände der generischen lokalen Namensauflösung
Enthält der aufzulösende Namensausdruck jedoch generische Namensteile (Wildcards) (vgl. Abschnitt 2.2.2.4), so kann die Auflösung in der Regel nicht bereits dann terminieren, wenn ein Namenseintrag ermittelt wurde. Im Extremfall wird sich die Erkundung über den gesamten Namensraum erstrecken (vgl. Abschnitt 4.1.1.1). Die mit der lokalen Auflösung generischer Namen verbundene vollständige Erkundung des Namensraums entspricht dann der rekursiven Tiefensuche. Werden bei der Auflösung eines Namens mehrere optionale Pfade ermittelt, so wird zunächst immer nur ein Namenspfad verfolgt. Optionale Pfade werden zunächst vermerkt und beschritten, sobald der erste Pfad vollständig abgesucht wurde. Im Zustandsdiagramm aus Abbildung 4.27 wird im Falle einer generischen Auflösung ausgehend vom Zustand found die Erkundung des Namensraums so lange fortgesetzt, bis kein alternativer Pfad mehr existiert.
Um bei der Auflösung optionale Pfade im Namensraum und Navigationsinformation in vorgehaltenen Namenseinträgen zu vermerken, verwaltet jeder Namensverwalter der dynamischen globalen Namensverwaltung eine kellerartige Datenstruktur (vgl. Abbildung 4.28). Bei Interpretation eines Namens werden eventuell auftretende optionale Pfade auf dem Keller vermerkt (push). Zunächst wird dann der erste Pfad verfolgt, bis ein Namenseintrag ermittelt wurde, der dem generischen Namensausdruck entspricht(found), oder keine weitere Interpretation mehr gelingt. Anschließend wird der oberste Pfad von Keller genommen (pop) und verfolgt, bis auch dieser erkundet ist, usw. Die lokale Auflösung generischer Namen terminiert, sobald der Keller leer ist (vgl. Abbildung 4.28).

Abbildung 4.28: Aufbau der Kellerstruktur bei der Auflösung generischer Namen
Außer zur rekursiven Interpretation generischer Namen findet der Keller Verwendung, um lokal vorgehaltene und replizierte Namenseinträge mit Navigationsinformation auf externe Namensverwalter zu vermerken und zu verfolgen. Solange der Name lokal aufgelöst werden kann, werden ermittelte externe Namenseinträge mit ihren Bezeichnern und der zugehörigen Navigationsinformation auf dem Keller abgelegt. Ist lokal keine weitere Interpretation möglich, so wird der Keller wieder abgebaut und die externen Namenseinträge werden verfolgt. Dieses Rückwärtsverfolgen externer Referenzen entspricht einer Art knotenübergreifenden rekursiven Tiefensuche. Führt ein externer Namenseintrag nicht zum Ziel, so wird auch er vom Keller genommen, bis schließlich der Verweis auf den übergeordneten Namensverwalter auf dem Keller liegt.
[AL14]Bei der Lokalisierung von Namenseinträgen befindet sich in jedem kontaktierten Namensverwalter ein solcher Keller und für jede Namensauflösung, die in der Namensverwaltung gleichzeitig abläuft, wird ein separater Keller aufgebaut. Ein Auflösungsvorgang wird zudem durch eine Transaktionsnummer gekennzeichnet. Nur lokale Mehrdeutigkeiten werden auf dem Keller abgelegt. Globale Mehrdeutigkeiten werden sofort parallel bearbeitet. Dadurch lassen sich globale Zustände vermeiden und es wird möglich, kontaktierte Namensverwalter weitgehend zustandslos zu implementieren. Alle kontaktierten Namensverwalter unterhalten ihrerseits jedoch für die lokale Bearbeitung von Anfragen jeweils einen Keller.
In Systemen, die Nebenläufigkeit durch separate Prozesse unterstützen (z.B. UNIX, Windows NT), kann als Alternative zur rekursiven Abarbeitung oder zur Einführung eines Kellers für jeden Pfad die Abspaltung separater Prozesse in Betracht gezogen werden. Dieses Vorgehen erscheint zunächst elegant, ist aufgrund der hohen Kosten für Prozesse und des durch die lokale Parallelität erforderlichen Koordinationsaufwands zur Vermeidung von Konflikten allerdings nur schwer realisierbar. Eine weitere Alternative stellt die Einführung sog. Cursors dar, wie sie beispielsweise zur Verwaltung von Optionen in der sog. Soup im objekt-orientierten Betriebssystem des Apple Newton [Apple, 93] verwendet werden.
4.4.2.2 [AL15][AL16]Globale Auflösung generischer Namen
Sind bei der Interpretation hierarchischer Namen externe Verweise zu verfolgen, so geht die Kontrolle der weiteren Auflösung des Namens an einen externen Namensverwalter über. Dieser interpretiert seinerseits den verbliebenen Namensteil so weit wie möglich. Falls erforderlich, kontaktiert dieser weitere Namensverwalter. Existieren für einen Namen mehrere externe Verweise, wie dies beispielsweise bei generischen Namen der Fall sein kann, so geht die Kontrolle gleichzeitig an mehrere Namensverwalter über. Um die globale Namensauflösung weitgehend zustandslos zu realisieren, werden optionale externe Referenzen im Gegensatz zu lokalen nicht rekursiv, sondern transitiv abgearbeitet. Dieses Vorgehen besitzt einen Zeitvorteil gegenüber dem rekursiven Verfahren und reduziert die Anzahl der notwendigen Nachrichten.
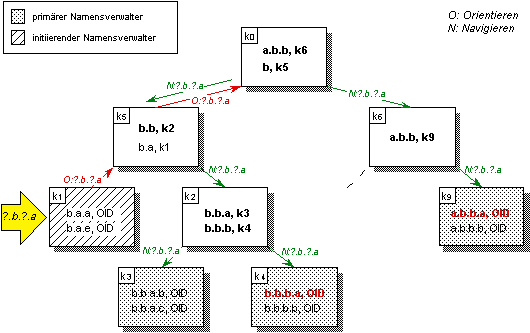
Abbildung 4.29: Beispiel einer generischen globalen Namensauflösung
Das Beispiel in Abbildung 4.29 zeigt die parallele Auflösung generischer globaler Namensanfragen bei Existenz von Verweisen auf externe Namensverwalter. Die Anfrage wandert in der Orientierungsphase zunächst in Richtung Wurzel der Verwalterhierarchie, bis ein Kontext ermittelt wird, in dem der gesuchte Namen vollständig enthalten ist. Hier wird der Name so weit wie möglich lokal interpretiert. Verweist ein Eintrag auf einen externen Namensverwalter, so geht die weitere Interpretation auf diesen über. In Abbildung 4.29 passen beispielsweise in Namensverwalter k2 mehrere Namenseinträge auf den gesuchten Namensteil, so daß für die weitere Auflösung des generischen Namens die Namensverwalter k3 und k4 kontaktiert werden.
Alternativ zu diesem Vorgehen kann bereits im ersten Namensverwalter, der die Anfrage erhält, der Name so weit wie möglich lokal aufgelöst werden. Kommen weitere Namensverwalter für die Bearbeitung der Anfrage in Betracht, d.h. der gesuchte Name ist nicht vollständig in einem lokalen Kontext enthalten, wird die Anfrage in der Verwalterhierarchie nach oben an andere Namensverwalter geleitet. Um Duplikate in Anfrageergebnissen zu vermeiden, dürfen Anfragen nicht in die Richtung weitergeleitet werden, aus der sie gekommen sind. Der Vorteil dieses Verfahrens ist in der rascheren Bearbeitung von Anfragen und in einer geringeren Nachrichtenanzahl zu sehen. Nachteilig für die Realisierung dieses Konzepts wirkt sich hingegen die aufwendigere Fallunterscheidung aus.
4.4.2.3 Beschränkung der Lokalisierung bei Auflösung generischer Namen
Vollständig spezifizierte Namen sind in ihrem Gültigkeitsbereich eindeutig. Daher terminiert die Bearbeitung vollständig spezifizierter Namensanfragen, sobald genau eine Antwort vom zuständigen Namensverwalter gegeben wurde. Demgegenüber liefern generische Namensanfragen häufig eine variable Anzahl von passenden Namenseinträgen als Ergebnis, wobei nicht trivial zu entscheiden ist, wann eine Namensanfrage terminiert.
Da Namensanfragen häufig synchron und interaktiv im Benutzerdialog initiiert werden, ist ein wesentliches Entwurfskriterium für die Namensverwaltung eine möglichst kurze Antwortzeit. Um diese zu begrenzen, kommen folgende Maßnahmen in Betracht:
• temporäre Restriktionen
Die Vorgabe eines Zeitlimits für die Beantwortung einer Namensanfrage läßt diese in jedem Fall terminieren, unabhängig davon, ob Ergebnisse geliefert wurden oder nicht. Auch bei Ausfällen im Verwalternetz kann so das Terminieren garantiert werden. Zeitschranken werden dabei sowohl im initiierenden Namensverwalter als auch in den kontaktierten Namensverwaltern vorgegeben. So kann das Propagieren von Namensanfragen an weitere Namensverwalter nach Ablauf einer vorgegebenen Zeitspanne unterbunden werden.
• Suchhorizonte
Namen in der dynamischen globalen Namensverwaltung sind ortsunabhängig. Daher ist zunächst keine direkte Beschränkung der räumlichen Ausdehnung von Anfragen auf eine bestimmte Lokalität anhand des Namens möglich. Für den Anwender ist die Lokation eines Namenseintrags transparent. Dennoch besteht ein Zusammenhang zwischen Namen und der Lokation ihrer administrativen Namenseinträge, da diese syntaxgesteuert plaziert werden. Die Beschränkung eines Namens auf einen bestimmten Kontext hat daher immer auch eine räumliche Begrenzung der Lokalisierung zur Folge.
Dieser Aspekt soll an einem Beispiel kurz erläutert werden: Enthält ein generischer Name „/a.b.a.?.a“ einen Platzhalter, so beschränkt sich die Lokalisierung auf den Kontext namens „/a.b.a“ und damit auf diejenigen Namensverwalter, die Namenseinträge für Namen in diesem Kontext enthalten. Eine Kante des Namensraums wird dabei nur so weit verfolgt, wie eine Übereinstimmung festgestellt wird. Ein Platzhalter der Form ?<1, >[5] hingegen bewirkt, daß ein Pfad so lange verfolgt wird, bis das Ende des Pfades erreicht ist, oder der Pfad die Anfrage nicht mehr erfüllen kann.
·
physische
Lokalisierungsbereiche
Die räumliche Ausdehnung der Lokalisierung kann durch Vorgabe eines physischen Lokalisierungsbereichs eingegrenzt werden. Die dynamische globale Namensverwaltung unterscheidet hierzu drei Bereiche der Lokalisierungsausdehnung:
• lokaler Namensverwalter: Die Lokalisierung bleibt auf den lokalen Namensverwalter beschränkt.
• Rechnerverbund: Die Lokalisierung wird nur im Rechnerverbund des initiierenden Namensverwalters an die vorhandenen Namensverwalter propagiert.
• globaler Bereich: Alle im Verwalternetz vorhandenen Namensverwalter werden in die Lokalisierung involviert.
Physische Suchhorizonte, wie sie beispielsweise im Namensdienst des DACNOS-Systems [Mattes, 91] Verwendung finden, sind in der dynamischen globalen Namensverwaltung aufgrund der Ortsunabhängigkeit der Namen nicht realisierbar. Eine weitere Möglichkeit zur Einschränkung der Lokalisierung ist die Begrenzung der Suchtiefe in der Verwalterhierarchie.
• quantitative Restriktionen
Ein wichtiges Kriterium zur Beschränkung der globalen Auflösung ist die Quantität der Namenseinträge, die als Resultat erwartet wird. Hierbei kann zwischen folgenden quantitativen Vorgaben differenziert werden:
• genau ein Eintrag: Das Verwalternetz wird so lange durchsucht, bis genau ein Eintrag gefunden wurde, der der gegebenen Beschreibung des Namens entspricht.
• genau i Einträge: Die Namensauflösung liefert genau i Namenseinträge und terminiert bei Erreichen der vorgegebenen Anzahl.
• alle Einträge: Eine vollständige Erkundung erstreckt sich über alle relevanten Namensverwalter des Verwalternetzes, bis der gesamte spezifizierte Bereich durchsucht ist.
Quantitative Vorgaben bei der Lokalisierung generischer Namenseinträge werfen lokal keine Probleme auf. In einer verteilten Umgebung hingegen ist das Terminieren einer Anfrage nicht ohne weiteres feststellbar. Während bei der rekursiven oder iterativen Tiefensuche in der Verwalterhierarchie relativ einfach zu entscheiden ist, ob alle relevanten Namensverwalter kontaktiert wurden oder die geforderte Anzahl von Einträgen geliefert haben, ist dies bei der parallelen Anfragebearbeitung nur unter einem erheblichen Aufwand von Kontrollnachrichten zu realisieren. Jeder Namensverwalter hat hier autonom zu entscheiden, ob die Gesamtzahl der geforderten Einträge erreicht ist oder nicht. Verfahren zur Entscheidung der Terminierung verteilter Algorithmen sind bekannt, erfordern jedoch einen hohen Aufwand und ein erhebliches Maß an Kontrollnachrichten (vgl. hierzu [Dykstra, 80] [Misra, 82] [Chandy, 85]).[AL17]
4.4.3 Globale Verwaltung attributierter Namen
Die Verwaltung attributierter Namen in der dynamischen globalen Namensverwaltung weist Parallelen zur Registrierung von Synonymen und zur Auflösung generischer Namen auf. Attributierte Namen zerfallen in orthogonale, hierarchische Teilnamen, die wie Synonyme separat im Namensraum syntaxgesteuert plaziert werden. Partielle Namen eines attributierten Namens, die eine bestimmte Eigenschaft eines Objekts beschreiben, können wie generische Namen mehrere Objekte bezeichnen. Vollständig spezifizierte attributierte Namen hingegen identifizieren ein Objekt wie hierarchische Namen eindeutig.
4.4.3.1 Registrierung attributierter Namen
Die dynamische globale Namensverwaltung plaziert hierarchische Namen syntaxgesteuert im Namensraum und generiert bei Bedarf neue Kontexte. Die in den vorangegangenen Abschnitten vorgestellten Verfahren zur globalen Registrierung von Namen lassen sich auf attributierte Namen ausdehnen, wie im folgenden dargestellt wird.
Hierarchische Strukturen können nur in der Art effizient durchsucht werden, in der sie organisiert sind. Sie eignen sich daher nur für die Organisation von Informationen, die entsprechend hierarchisch strukturiert sind. Um eine effiziente globale Lokalisierung von Attributen in hierarchischen Namensräumen zu ermöglichen, bricht die dynamische globale Namensverwaltung daher bei der Registrierung attributierte Namen in hierarchische Teilnamen auf, die zueinander orthogonale Attribute benennen. Orthogonale Attribute mit ihren Werten bilden separate hierarchische Teilbäume im globalen hierarchischen Namensraum, die unabhängig voneinander auf die Verwalterhierarchie abgebildet werden. Der Namensraum wird somit flacher und kann effizienter nach Attributen durchsucht werden (vgl. Kapitel 2). Teilnamen bezeichnen jeweils Teilordnungen von Attributen, deren Reihenfolge nicht vertauschbar ist. Attribute selbst setzen sich aus Attributtyp und Attributwert zusammen:
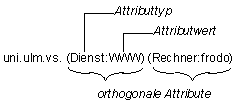
Wie in Kapitel 2 bereits diskutiert, lassen sich implizite und explizite Attribute unterscheiden. Attributtypen werden stets im Namensraum repräsentiert, während Attributwerte nur im Namensraum abgelegt werden können, wenn sie einen diskreten und beschränkten Wertebereich aufweisen. Attributwerte mit kontinuierlichem oder variablem Wertebereich müssen als implizite Attribute in den Namenseinträgen repräsentiert werden, da sie keine eindeutige Vergleichsoperationen zulassen und zudem ständigen Veränderungen unterworfen sind, die sich auf den Namensraum auswirken würden. Häufig werden implizite Attributwerte auch erst zum Zeitpunkt der Namensauflösung bestimmt.
explizite
Attributwerte: (Form.rund)
(Farbe.rot)
implizite
Attributwerte: (Größe:175,6)
(Gewicht:67,4)[AL18]
Die Registrierung attributierter Namen verläuft ähnlich dem Registrieren synonymer Namen (vgl. Abschnitt 4.4.1). Unterschiede bestehen jedoch darin, daß orthogonale Teilnamen, die als Synonyme aufgefaßt werden können, nicht eindeutig sein müssen. Zur Registrierung wird zunächst der attributierte Name in Teilnamen zerlegt, die jeweils orthogonale Attribute bezeichnen. Für alle im Namensraum repräsentierten Attribute eines Objekts werden dann separat Namenseinträge im Verwalternetz syntaxgesteuert plaziert. Zusätzlich werden analog zur Registrierung von Synonymen im primären Namensverwalter alle orthogonalen Attribute mit abgelegt.
Abbildung 4.30: Repräsentation expliziter und impliziter Attribute im Namensraum
Namenseinträge von Objekten, deren Eigenschaften im Namensraum repräsentiert werden, sind relativ einfach zu lokalisieren. Wesentlich aufwendiger dagegen gestaltet sich die Lokalisierung von Objekten anhand von impliziten Attributen, deren Attributwerte nicht im Namensraum, sondern im individuellen Namenseintrag enthalten sind. Um Namenseinträge mit impliziten Attributwerten zu lokalisieren, legt die dynamische globale Namensverwaltung die zugehörigen Attributtypen stets im Namensraum ab (vgl. Abbildung 4.30).
Vollständig spezifizierte attributierte Namen identifizieren ein Objekt eindeutig. Ist die Eindeutigkeit eines attributierten Namens in einem für einen Teilnamen zuständigen Namensverwalter nicht gegeben, so ist diese auch in den Namensverwaltern der übrigen partiellen Namen verletzt. Die Registrierung wird in allen Namensverwaltern abgebrochen, ohne daß eine Abstimmung der einzelnen Namensverwalter notwendig wäre.
Werden zusätzliche Attribute zu einem Objekt nachträglich registriert, so geschieht dies in der Regel im primären Namensverwalter, in dem auch die bisherigen Attribute abgelegt wurden. Wird ein Attribut für ein Objekt in einem anderen Namensverwalter registriert, so wurde der Objekt-Bezeichner dieses Attributs nur über einen Namen ermittelt. In diesem Fall werden jedoch alle Navigationsinformationen lokal vorgehalten, so daß der primäre Namensverwalter lokalisiert und das neue Attribut auch dort abgelegt werden kann (vgl. Registrierung von Synonymen in Abschnitt 4.4.1).
4.4.3.2 Auflösung attributierter Namensanfragen
Attributierte Anfragen, die an Namensverwaltungen gestellt werden, lassen sich in folgende Kategorien einordnen:
1. Identifikation von Objekten anhand spezifizierter Eigenschaften: Anfragen sind von der Form „Welche Objekte besitzen die Eigenschaft x?“ und liefern die zugehörigen Objekt-Bezeichner.
2. Ermittlung der Eigenschaften eines bestimmten Objekts: Anfragen sind von der Form „Welche Eigenschaften hat ein bestimmtes Objekt?“. Die Namensverwaltung liefert eine Folge von Attributen mit den zugehörigen Werten.
3. Verifizierung von Eigenschaften eines gegebenen Objekts: Anfragen sind von der Form „Hat ein gegebenes Objekt eine bestimmte Eigenschaft?“. Als Resultat liefert die Namensverwaltung einen boolschen Wert.
Für die Identifizierung eines Objekts übergibt der Benutzer der Namensverwaltung eine Beschreibung der gewünschten Eigenschaften in Form eines attributierten Namens. Diese Beschreibung muß jedoch nicht notwendigerweise eindeutig sein. Insbesondere können Teilnamen, die eine bestimmte Eigenschaft eines Objekts beschreiben, an eine Menge von Objekten gebunden sein. Erst die vollständige Spezifizierung der Eigenschaften eines Objekts in Form eines attributierten Namens identifiziert dieses eindeutig.
Bei der Identifizierung von Objekten anhand attributierter Namen ist die Attributreihenfolge signifikant. Die Attribute innerhalb eines partiellen Namens bilden eine Teilordung, weshalb dessen Auflösung streng sequentiell erfolgt. Einzelne Teilordungen orthogonaler Attribute hingegen repräsentieren jeweils unabhängige Eigenschaften eines Objekts und können daher in der Reihenfolge vertauscht werden (z.B. (x.y.z)(a.b.c.d) <-> (a.b.c.d)(x.y.z)). Die Lokalisierung der zugehörigen Namenseinträge kann somit parallel erfolgen. Dieses Vorgehen entspricht der Auflösung generischer Namen (vgl. Abbildung 4.29).
[AL19]Es stellt sich nun die Frage, wie global Objekte mit logisch verknüpften Eigenschaften ermittelt werden, wenn einem Objekt in Namensverwalter k1 die Eigenschaft a zugeordnet ist und in Namensverwalter k2 die Eigenschaft b? Für die Lösung dieses Problems gibt es zwei mögliche Ansätze:
1. Verknüpfungen von Attributen können stets im primären Namensverwalter behandelt werden. Falls ein Namensverwalter einen Namenseintrag enthält, der eine bestimmte Eigenschaft eines Objekts repräsentiert, so sind in diesem Namensverwalter auch Namenseinträge für alle übrigen Attribute registriert.[AL20]
2. Jeder Namensverwalter, der eine attributierte Anfrage teilweise erfüllen kann, da er bestimmte Attribute verwaltet, liefert sein Teilergebnis. Der initiierende Namensverwalter verknüpft dann die Menge der zurückgelieferten Namenseinträge entsprechend der gestellten Anfrage zur Resultatmenge.[AL21]
Erste Methode ist bei der Auflösung attributierter Namen vorzuziehen, da sie weniger Antwortnachrichten erzeugt. Allerdings muß eine Anfrage dabei stets den gesamten attributierten Namen enthalten, da andernfalls im primären Namensverwalter nicht entschieden werden kann, ob die vorhandenen Namenseinträge die Anfrage ganz oder nur teilweise erfüllen.
Die globale Verwaltung synonymer und attributierter Namen sowie die Behandlung generischer Namensanfragen werden in der dynamischen globalen Namensverwaltung durch Verfahren abgedeckt, die sich aus den grundlegenden globalen Namensoperationen herleiten.
4.5 Beurteilung der Plazierung von Namen im Verwalternetz
Das vorangegangene Kapitel hat gezeigt, wie hierarchische, synonyme und attributierte Namen unabhängig von physikalischen oder organisatorischen Strukturen selbständig und ohne Administration in globalen Namensräumen verwaltet werden.
Durch die hierarchische Organisation des Namensraums und der Namensverwalter kann die Zahl der zur Namensauflösung erforderlichen Navigationsschritte reduziert werden, indem Namenseinträge mit Navigationsinformation syntaxgesteuert im Verwalternetz plaziert werden. Die maximale Hierarchiestufe, auf der Namenseinträge in der Verwalterhierarchie positioniert werden, entspricht dabei stets der Anzahl der Namensteile. Die zur globalen Namensauflösung erforderliche Navigationsinformation wird bei der Plazierung der Namenseinträge selbständig erzeugt. Die Bildung von Kontexten reduziert ferner die in den Namensverwaltern zur Lokalisierung primärer Namenseinträge notwendige Navigationsinformation. Die syntaxgesteuerte Plazierung von Namen verhindert ferner, daß übergeordnete Kontexte in unteren Hierarchiestufen entstehen und umgekehrt.
Trotz der zahlreichen Vorzüge der syntaxgesteuerten Plazierung von Namenseinträgen und der Bildung von Kontexten läßt die dynamische Verwaltung globaler Namen auch einige Nachteile erkennen, die sich auf die Effizienz und Ausfallsicherheit der Namensverwaltung auswirken:
1. Der Registrierungsort des ersten Namens ist ausschlaggebend für die Plazierung weiterer ähnlicher Namen. Somit besteht das Problem, daß administrative Namenseinträge ungünstig im Verwalternetz plaziert werden, falls ähnliche Namen später vorwiegend in einem anderen Teil des Verwalternetzes registriert werden. Hierdurch entsteht eine gewisse Ineffizienz und ein erhöhter Nachrichtenaufwand bei der Registrierung von Namenseinträgen.
2. Die Lokalisierung von Namen ist ineffizient, falls Namen in Teilen des Verwalternetzes angefragt werden, in denen die zugehörigen administrativen Namenseinträge nicht plaziert sind.
3. Befindet sich der administrative Namensverwalter eines Namens in einem anderen Bereich des Verwalternetzes als der primäre Namensverwalter, so kann es vorkommen, daß bei Netzwerkpartitionierung der globale Name nicht aufgelöst werden kann, obwohl der primäre Namenseintrag und das Objekt selbst erreichbar sind.
Das nachfolgende Kapitel diskutiert diese Probleme und zeigt Lösungsmöglichkeiten auf. Durch Verfahren zur Replikation von Namenseinträgen wird der Nachrichtenaufwand bei der Lokalisierung und der Registrierung erheblich reduziert. Gegenstand der Betrachtungen des nächsten Kapitels sind zudem Maßnahmen zur Aufrechterhaltung der Funktionsfähigkeit der Namensverwaltung bei Ausfall einzelner Namensverwalter und bei Partitionierung des Verwalternetzes. Diskutiert werden auch Lösungen für Konsistenzprobleme, die sich aus der Replikation von Namenseinträgen und aus Ausfällen ergeben.
Die dynamische globale Namensverwaltung ermöglicht die selbständige Verwaltung eines globalen Namensraums. Aus der Dynamik der Verfahren erwachsen jedoch Effizienz- und Konsistenzprobleme, die durch Maßnahmen zur Replikation und Konsistenzerhaltung kompensiert werden müssen.