Zwei grundlegende Probleme, die bei der Verwaltung globaler Namensräume bestehen, wurden bisher noch nicht ausreichend diskutiert, die Verfügbarkeit und die Konsistenz von Namenseinträgen.
· Eine hohe Verfügbarkeit äußert sich zum einen durch kurze Antwortzeiten und zum anderen durch eine hohe Ausfallsicherheit der Namensverwaltung. Die Antwortzeiten bei Lesezugriffen können durch das Vorhalten und durch die Replikationen von Namenseinträgen verbessert werden. Eine hohe Ausfallsicherheit hingegen ist schwieriger zu erreichen, da sie sehr eng mit der Zuverlässigkeit eines verteilten Systems verbunden ist.
· Der Konsistenz der Namenseinträge muß gerade bei der dynamischen Verwaltung von Namensräumen besondere Bedeutung zugemessen werden, da Änderungen im Namensraum dynamisch erfolgen und nicht durch einen Administrator koordiniert werden. Die Einführung von Replikation verschärft das Konsistenzproblem zusätzlich.
Das folgende Kapitel behandelt Verfahren zur Replikation und zur Konsistenzerhaltung von Namenseinträgen in der dynamischen globalen Namensverwaltung. Eine tragende Rolle spielt hierbei der Aspekt der Ausfallsicherheit und der Fehlertoleranz.
5.1 Vorhalten von Namenseinträgen
Die Einführung von Replikation in verteilten Systemen hat ihre Begründung in der Verbesserung der Verfügbarkeit der verwalteten Ressourcen. In der Praxis ist die Unterscheidung zwischen aktiver und passiver Replikation sinnvoll. Aktive Replikation findet beispielsweise statt, wenn bei der Registrierung neuer Einträge diese redundant gespeichert werden. Sie trägt in erster Linie zur Steigerung der Ausfallsicherheit bei. Das Vorhalten globaler Einträge, auch als passive Replikation (Vorhalten, Caching) bekannt, dient primär der Steigerung der Zugriffsgeschwindigkeit bei wiederholten Lesezugriffen auf extern verwaltete Namenseinträge.
Eine der wesentlichen Anforderungen an globale Namensverwaltungen besteht darin, einen leistungsfähigen Zugriff auf Objekte über Namen bereitzustellen. Zur Steigerung der Zugriffseffizienz und zur Reduzierung der Netzwerkzugriffe halten Klienten eine Liste mit Präfixkomponenten von Namen bekannter Namensverwalter, die zum verkürzten Zugriff genutzt werden kann [Cheriton, 84a], [Cheriton, 89], [Welch, 86]. Zusammen mit jedem Präfix wird der Bezeichner des betreffenden Objekts oder Kontexts, der durch das Ende eines Namenspfades bezeichnet wurde, und die Identifikation des zuständigen Namensverwalters gespeichert. Eine wiederholte Anfrage nach demselben Namen kann dann lokal aufgelöst werden, ohne weitere Namensverwalter mit einbeziehen zu müssen. Gerade die häufig besuchten Wurzeleinträge in hierarchischen Namensräumen ändern sich sehr selten, so daß sie für die Replikation prädestiniert sind.
In vielen existierenden Namensverwaltungen werden vorgehaltene Namenseinträge in einem separaten Cache gehalten. Ein Cache im Sinne der Namensverwaltung ist ein zusätzlicher und möglicherweise beschränkter Speicher, der in einem Namensverwalter verwaltet wird, um die Ergebnisse einer vorangegangenen Auflösung eines globalen Namens vorzuhalten. Eine erneute Anfrage nach demselben Namenseintrag kann anschließend mit einem erheblichen Zeitvorteil lokal aufgelöst werden [Gopal, 89]. Dabei hat sich als sinnvoll herausgestellt, nicht nur erfolgreiche Anfragen vorzuhalten, sondern auch fehlgeschlagene, so daß diese bei erneuten Anfragen übergangen werden können.
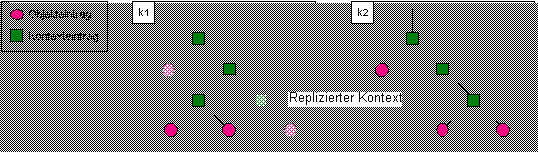
Abbildung 5.1: Vorhalten von Namenseinträgen in den Namensbasen von Namensverwaltern
In der aktuellen Implementierung der dynamischen globalen Namensverwaltung gibt es für die Verwaltung vorgehaltener Namenseinträge keine gesonderte Datenstruktur. Replizierte Namenseinträge werden zusammen mit lokalen und globalen Namenseinträgen in der lokalen Namensbasis eines Namensverwalters abgelegt. Lediglich ein Attribut des Namenseintrags unterscheidet Originaleinträge von vorgehaltenen Namenseinträgen (vgl. Anhang C). Das Beispiel in Abbildung 5.1 zeigt replizierte Namenseinträge in den Namensbasen zweier Namensverwalter (Replizierte Einträge sind schraffiert dargestellt).
5.1.1 Namensauflösung in Präsenz vorgehaltener Namenseinträge
Bei der globalen Auflösung hierarchischer Namen wird versucht, Namen unter Verwendung lokaler und vorgehaltener Einträge einer früheren Anfrage möglichst weit lokal zu interpretieren. Dieses Vorgehen wird als Prefixing bezeichnet. Je nach Grad der Übereinstimmung eines absoluten Namens (Name mit absoluter Pfadangabe) mit einem gespeicherten Präfix können folgende Fälle unterschieden werden [Authenried, 90] [Welch, 86]:
• Volltreffer (hit): Die Präfixliste des initiierenden Namensverwalters enthält zu einem Namen einen Verweis auf den zuständigen Namensverwalter. Der Klient wendet sich daher mit dem Namen direkt an den Namensverwalter und erhält die Identifikation des Objekts, mit der er schließlich die gewünschte Operation initiiert (vgl. Abbildung 5.2, Fall ¿).
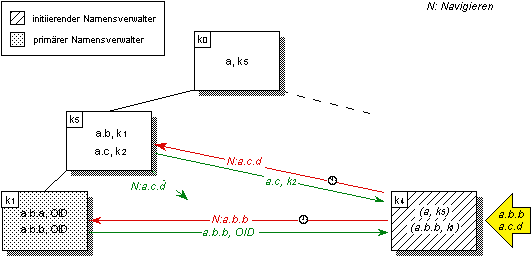
Abbildung 5.2: Namensauflösung mit Hilfe vorgehaltener Namenseinträge im initiierenden Namensverwalter
• Schwacher Treffer (near miss): Die Präfixliste enthält den Eintrag eines globalen Kontextes, der den aufzulösenden Namen enthält. Im Fall eines vorgehaltenen Kontexts kontaktiert der initiierende Namensverwalter den zugehörigen externen Namensverwalter. Dieser führt die Auflösung fort und liefert die Resultate an den initiierenden Namensverwalter zurück. Letzterer legt diese Informationen in der Präfixliste ab und fährt wie im Fall des Volltreffers fort (vgl. Abbildung 5.2, Fall ¡).
• Kein Treffer (complete miss): Die Präfixliste enthält keinen Eintrag. In diesem Fall werden unter Zuhilfenahme der Konfigurationsinformation in der Orientierungsphase alle erreichbaren übergeordneten Namensverwalter der Verwalterhierarchie auf Vorliegen des betreffenden Namens geprüft. Auf der Basis der Rückmeldung wird ein Eintrag in die Präfixliste aufgenommen.
Der hier beschriebene Mechanismus des Präfixvergleichs führt zur Entlastung der Namensverwalter globaler Kontexte, so daß der Durchgang durch den Wurzelkontext in einem hierarchisch organisierten Namensraum nicht zum Engpaß des Systems wird. Nur wenn lokal nicht ausreichend Informationen über einen Namen verfügbar sind, ist es notwendig, auf die Namenseinträge übergeordneter Namensverwalter zurückzugreifen. Dabei ist zunächst nicht klar, welcher Namensverwalter für die weitere Interpretation eines Namens zuständig ist. [AL1]
5.1.2 Vorhalten von Namenseinträgen in lokalen Namensverwaltern
Prinzipiell gibt es zwei Arten des Vorhaltens von Namenseinträgen: Lokale und regionale Caches. In der ersten Methode speichern individuelle Namensverwalter die Ergebnisse einer globalen Namensauflösung im lokalen Cache. Jede Anfrage nach einem globalen Namen wird zuerst mit dem lokalen Cache verglichen. Die globale Auflösung wird nur notwendig, wenn kein passender Eintrag im Cache vorhanden ist. Das Ergebnis der Auflösung wird für weitere Anfragen in den lokalen Cache aufgenommen. Gekoppelt mit der iterativen oder verweisenden Suche ist das lokale Vorhalten sehr effizient anzuwenden.
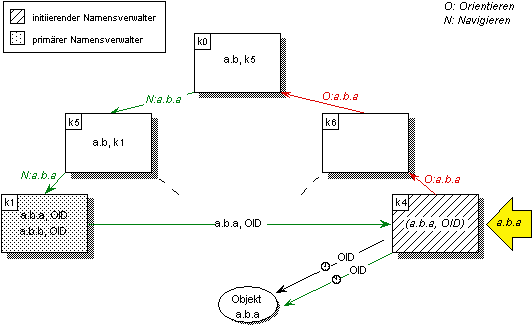
Abbildung 5.3: Vorhalten von Namen-Objekt-Bindungen im initiierenden Namensverwalter
Die dynamische globale Namensverwaltung verwendet aus Effizienzgründen ein transitives Verfahren zur Lokalisierung globaler Namenseinträge. Der initiierende Namensverwalter erhält daher zunächst keine Zwischenergebnisse der Namensauflösung, die er für wiederholte Anfragen verwenden könnte. Falls direkt der Objekt-Bezeichner als Resultat auf eine Anfrage geliefert wird, kann der initiierende Namensverwalter für wiederholte Anfragen lediglich die Namen-Objekt-Bindung vorhalten.
Das Beispiel in Abbildung 5.3 zeigt den Vorgang der transitiven Namensauflösung beim erstmaligen Objektzugriff ¿ und den Rückgriff auf die vorgehaltene Namen-Objekt-Bindung beim wiederholten Objektzugriff ¡. Der in Namensverwalter k4 vorgehaltene Namenseintrag wird in Klammern dargestellt.
Das Vorhalten primärer Namenseinträge mit Namen-Objekt-Bindung hat den Nachteil, daß Inkonsistenzen in den vorgehaltenen Namenseinträgen unvermeidbar sind, sobald sich die Namen-Objekt-Bindung ändert. Die Aktualität vorgehaltener Namen-Objekt-Bindungen kann nur durch global eindeutige Objekt-Bezeichner festgestellt werden. Im Falle einer Inkonsistenz werden die vorgehaltenen Einträge invalidiert, und der Name erneut global aufgelöst. Anstelle des Objekt-Bezeichners kann jedoch auch eine Referenz auf den primären Namensverwalter eines Namens vorgehalten werden. Dieses Vorgehen erweist sich durch den zusätzlichen Indirektionsschritt als weniger effektiv, wirkt sich jedoch positiv auf die Konsistenz vorgehaltener Namenseinträge aus.
Wurde ein Name einmal aufgelöst, so ist es sehr unwahrscheinlich, daß derselbe Name unmittelbar anschließend vom selben Knoten erneut angefragt wird. Dies ist nicht in den Interaktionsmustern der Anwender begründet, sondern resultiert vielmehr aus der Tatsache, daß Applikationen i.d.R. nach der einmaligen Auflösung eines Namens intern mit dem Objekt-Bezeichner arbeiten. Wesentlich wahrscheinlicher hingegen ist es, daß ein Knoten unmittelbar anschließend einen Namen aufzulösen versucht, der im selben übergeordneten Kontext wie der zuvor aufgelöste Name enthalten ist. Hierfür ist jedoch eine vorgehaltene Namen-Objekt-Bindung oder eine Referenz auf den primären Namensverwalter wertlos.
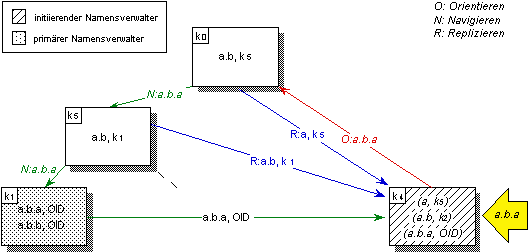
Abbildung 5.4: Vorhalten von Kontexteinträgen auf initiierenden Namensverwaltern
Um im oben geschilderten Fall die Zugriffseffizienz zu steigern, ist es notwendig, auch aufgelöste partielle Namen für Kontexte lokal vorzuhalten. Im Falle der iterativen Namensauflösung ist dies mit geringem Aufwand zu realisieren, da alle ermittelten Teilergebnisse an den initiierenden Namensverwalter zurückgegeben werden. Die transitive Namensauflösung hingegen erfordert die aktive Übermittlung von Teilergebnissen an den initiierenden Namensverwalter zu Replikationszwecken (vgl. Abbildung 5.4). Die so vorgehaltenen Teilergebnisse können lokal genutzt werden, um ähnliche Namen im selben Kontext effizienter aufzulösen.
5.1.3 Vorhalten von Namenseinträgen in übergeordneten Namensverwaltern
Die zweite, in globalen Namensverwaltungen wie DNS [Mockapetris, 88] häufig verwendete Caching-Methode sieht einen Namensverwalter als Regional Server vor, dem alle erfolgreichen oder fehlgeschlagenen Versuche zur Namensauflösung mitgeteilt werden. In einer hierarchischen Verwalterstruktur ist der Regional Server der übergeordnete Namensverwalter im Baum. Dieser wird gewöhnlich in die verkettete oder rekursive Suche mit einbezogen. Ein eventuelles Ergebnis wird anschließend zuerst in den Cache des Regional Servers aufgenommen, bevor es an den Initiator der Anfrage weitergegeben und dort der lokale Cache angepaßt wird. Dieses Vorgehen ergänzt die Namensauflösung durch vorgehaltene Namenseinträge für die Region. Da der Regional Server die vorgehaltenen Daten besitzt, kann er versuchen, die Anfrage in der Region zu lösen, bevor die globale Auflösung aufgenommen wird. Im Design vieler Namensverwaltungen vorzufinden ist eine Kombination aus der lokalen und der regionalen Methode.
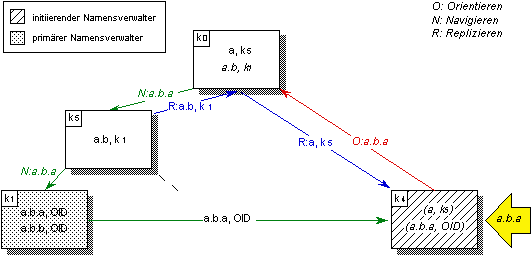
Abbildung 5.5: Vorhalten von Namenseinträgen in übergeordneten Namensverwaltern
Das Vorhalten von Namenseinträgen in lokalen oder regionalen Namensverwaltern hat jedoch nur Vorteile für wenige Namensverwalter, die dem Regional Server direkt untergeordnet sind. Zudem erfolgt die Namensauflösung in der dynamischen globalen Namensverwaltung transitiv, so daß die involvierten Namensverwalter keine Zwischenergebnisse der Auflösung zurückerhalten. Die dynamische globale Namensverwaltung verfolgt daher eine Strategie des Vorhaltens, die übergeordnete Namensverwalter so integriert, daß möglichst viele untergeordnete Namensverwalter von vorgehaltenen Namenseinträgen profitieren. Dazu wird jeweils das Ergebnis einer partiellen Namensauflösung an den im vorangegangenen Auflösungsschritt kontaktierten Namensverwalter zurückgegeben (vgl. Abbildung 5.5). Hierdurch kann die Anzahl der notwendigen Auflösungsschritte bei jeder erneuten Anfrage desselben Namens halbiert werden. Gleichzeitig wandern übergeordnete Kontexte zu untergeordneten Namensverwaltern und untergeordnete Kontexte zu übergeordneten Namensverwaltern. Dieses Vorgehen bewirkt, daß bei jeder ähnlichen Anfrage der Weg zum primären Namensverwalter verkürzt wird.
Kontaktiert der initiierende Namensverwalter bei der Namensauflösung direkt den Namensverwalter an der Wurzel der Verwalterhierarchie, so können in die Auflösung nur die im initiierenden Namensverwalter lokal vorgehaltenen Einträge einbezogen werden. Um vorgehaltene Einträge in übergeordneten Namensverwaltern nutzen zu können, muß die Anfrage schrittweise nach oben zur Wurzel geleitet werden.
Das Vorhalten von Namenseinträgen steigert die Effizienz der globalen Namensauflösung.
5.2 Fehlertoleranz durch Replikation in globalen Namensverwaltungen
Durch die Einführung von Replikation in globalen Namensverwaltungen wird allgemein versucht, eine Verbesserung der Verfügbarkeit der verwalteten Namen zu erzielen und somit eine größere Ausfallsicherheit der Namensverwaltung zu erreichen. Replikation erfolgt in der dynamischen globalen Namensverwaltung durch das präventive Registrieren redundanter Namenseinträge mit Navigationsinformation.
5.2.1 Granularität ausgefallener Systemkomponenten
Verteilte Systeme müssen auf das Fehlverhalten einzelner Systemkomponenten und den Ausfall einzelner Teile des Gesamtsystems adäquat reagieren. Prinzipiell können alle Teile einer globalen Namensverwaltung ausfallen, angefangen von ganzen Netzwerkbereichen, über einzelne Netzwerksegmente und Kommunikationsverbindungen, über Namensverwalter bis hin zu einzelnen Speicherbereichen. Dabei lassen sich grundsätzlich drei verschiedene Fehlermöglichkeiten unterscheiden (vgl. auch Abbildung 5.6):
• Ausfall eines einzelnen Namensverwalters in der Verwalterhierarchie, wobei die übrigen Namensverwalter weiterhin aktiv sind.
• Ausfall eines Netzwerksegments, wobei der Rest des Systems weiterarbeitet, der andere Teil jedoch inaktiv ist.
• Ausfall einer Kommunikationsverbindung zwischen Teilen des Verwalternetzes, so daß diese nicht mehr zueinander in Verbindung stehen, jedoch jeder Teil für sich weiterhin aktiv ist (Partitionierung).
Als Maß für den Ausfall eines Namensverwalters dient die Wahrscheinlichkeit einer Fehlfunktion und die Größe der Speichereinheit. Die Verfügbarkeit von Kommunikationsverbindungen wird maßgeblich durch die Übertragungsgeschwindigkeit, die Ausfallwahrscheinlichkeit und die Semantik der Kommunikationsverbindungen bestimmt (vgl. Tabelle 3.4).

Abbildung 5.6: Ausfall von Speicherlokalitäten und Partitionierung des Systems
Der Ausfall einzelner Namensverwalter und Bereiche des Verwalternetzes kann als Spezialfall einer Partitionierung des Verwalternetzes betrachtet werden, wobei die betroffenen Komponenten inaktiv bleiben und keine Änderung der Namenseinträge im ausgefallenen Teil erfolgt. Der Ausfall eines Namensverwalters in der Verwalterhierarchie hat u.U. auch die Auftrennung des Verwalternetzes zur Folge.
5.2.2 Maßnahmen zur Steigerung der Ausfallsicherheit
Der folgende Abschnitt beschäftigt sich mit der Frage, wie Ausfälle in der Namensverwaltung behandelt und vermieden werden können. Falls ein Ausfall nicht zu vermeiden war, muß das System wieder einen konsistenten Zustand annehmen. Besonders schwierig ist das im Falle von Partitionen, wobei die einzelnen Teile der Namensverwaltung unabhängig voneinander weitergearbeitet haben (vgl. Abschnitt 5.3).
Je nach Grad des Ausfalls von Instanzen der Namensverwaltung können verschiedene Maßnahmen zur Anwendung kommen. Die Funktionsfähigkeit der dynamischen globalen Namensverwaltung bei Ausfall ganzer Netzwerkbereiche und einzelner Namensverwalter wird durch
· die Replikation von Namenseinträgen entlang des Pfades vom primären Namensverwalter zur Wurzel der Verwalterhierarchie,
· das Vorhalten von Namenseinträgen in übergeordneten Namensverwaltern,
· die Replikation von Namensverwaltern bei der Konfigurierung des Verwalternetzes und
· die Rekonfigurierung des Verwalternetzes, sobald der Zusammenhang der Verwalterhierarchie nicht mehr gegeben ist,
sichergestellt. Das Vorhalten von Namenseinträgen in übergeordneten Namensverwaltern wurde bereits im vorhergehenden Abschnitt vorgestellt, die übrigen Maßnahmen werden im folgenden diskutiert.
5.2.2.1 Replikation von Namenseinträgen auf dem Pfad zur Wurzel
Die dynamische globale Namensverwaltung plaziert Namenseinträge mit Navigationsinformation syntaxgesteuert im Verwalternetz, d.h. administrative Namenseinträge werden nicht notwendigerweise in dem Teil des Verwalternetzes plaziert, in dem sich die zugehörigen Objekte befinden. Somit kann der Objektzugriff über Namen bei Netzwerkpartitionierung beeinträchtigt sein, auch wenn das Objekt selbst vom Initiator der Namensanfrage aus erreichbar ist.
Um diese Situation zu vermeiden, werden globale Namenseinträge in administrativen Namensverwaltern lediglich mit Navigationsinformation auf den primären Namensverwalter versehen. Die eigentliche Namen-Objekt-Bindung hält der primäre Namensverwalter, in dem der Name ursprünglich registriert wurde. Da der primäre Namensverwalter und der Objektverwalter in der Regel identisch sind, ist die lokale Namensauflösung selbst dann möglich, wenn die Netzwerkpartition des Objektverwalters vom globalen Netzwerk und vom administrativen Namensverwalter isoliert ist.
Eine weitere Steigerung der Verfügbarkeit kann erreicht werden, wenn ein Namenseintrag mit Navigationsinformation, die zum primären Namensverwalter führt, nicht nur im administrativen Namensverwalter kadmin(n) und in den Namensverwaltern auf dem Pfad von der Wurzel der Verwalterhierarchie k0 zu diesem abgelegt werden, sondern als Replikate auch in den Namensverwaltern auf dem Pfad path(n):= k0,…,kprim(n) von der Wurzel der Verwalterhierarchie k0 zum primären Namensverwalter kprim(n) (vgl. Abbildung 5.7). Diese Replikationsmaßnahme gewährleistet, daß im Falle einer Netzwerkpartitionierung alle Objekte über Namen zugegriffen werden können, die sich in derselben Netzwerkpartition wie der Initiator der Anfrage befinden.
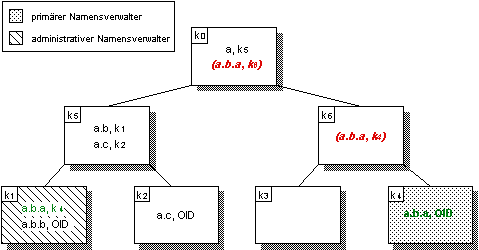
Abbildung 5.7: Replikation von Namenseinträgen auf den Pfad zu Wurzel
Die Plazierung replizierter Namenseinträge im Verwalternetz erfolgt ausschließlich entlang des Pfades path(n):= k0,…,kprim(n) von der Wurzel der Verwalterhierarchie zum primären Namensverwalter und ist nicht syntaxorientiert. Ähnlich der syntaxgesteuerten Plazierung administrativer Namenseinträge werden replizierte Namenseinträge zu Kontexten zusammengefaßt. Hierdurch wird eine erhebliche Reduzierung der replizierten Namenseinträge in den Namensverwaltern erreicht. Allerdings können hierbei dieselben replizierten Kontexte auf verschiedenen Pfaden im Verwalternetz entstehen, so daß die Navigation anhand replizierter Kontexteinträge nicht notwendigerweise eindeutig ist.
5.2.2.2 Replikation von Namensverwaltern
Durch das soeben vorgestellte Replikationsschema für Namen auf dem Pfad zum primären Namensverwalter kann die Verfügbarkeit eines Namens bei Netzwerkpartitionierung erhöht werden. Doch selbst dann, wenn das Kommunikationsnetzwerk zusammenhängend ist, kann der Ausfall einzelner Namensverwalter u.U. das Verwalternetz partitionieren.
Bisher wurde bei der Namensauflösung davon ausgegangen, daß ein Kontext durch genau einen Namensverwalter verwaltet wird. Um die Fehlertoleranz der Namensverwaltung bei Ausfall einzelner Namensverwalter zu erhöhen, müssen Namenseinträge für Kontexte bei mehreren Namensverwaltern repliziert werden. Eine Namenskomponente kann somit interpretiert werden, solange wenigstens ein Namensverwalter für den zugehörigen Kontext verfügbar ist; bei n Namensverwaltern pro Kontext werden also n-1 Ausfälle von Namensverwaltern toleriert. Eine solche Replikation ist vor allem auf den oberen Ebenen der Verwalterhierarchie von Bedeutung, da ein Ausfall hier jeweils die gesamte untergeordnete Partition des Namensraums isoliert. Detaillierte Betrachtungen zur Replikation von Namensverwaltern und eine formale Beschreibung der Abhängigkeiten zwischen Replikationen finden sich insbesondere in [Sinha, 92].
Abbildung 5.8 zeigt die Replikation des Kontexts „a.b“ bei den Namensverwaltern k2, k3 und k4. Die Navigationsinformation, die auf diese Namensverwalter verweist, ist ebenfalls repliziert. Jeder dieser Namensverwalter kennt alle Namensverwalter, die übergeordnete Kontexte enthalten. Genauso kennt ein übergeordneter Namensverwalter jeweils alle zuständigen Namensverwalter für einen bestimmten untergeordneten Kontext. Die Replikation spiegelt sich somit sowohl in der Konfigurations- als auch in der Navigationsinformation der Namensverwalter wieder. Jeder Namensverwalter vermerkt in seiner Replikationsinformation, welche Namensverwalter seine Namenseinträge replizieren. Replizierte Namensverwalter befinden sich in der dynamischen globalen Namensverwaltung stets auf derselben Stufe der Verwalterhierarchie und im selben Netzwerkbereich (vgl. Kapitel 3).[AL2]
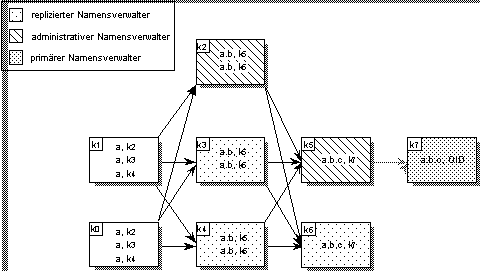
Abbildung 5.8: Beispiel für die Namensauflösung bei Replikation von Namensverwaltern
Die Interpretation eines Namensteils kann nun durch jeden Namensverwalter, der einen Namenseintrag für den zugehörigen Kontext enthält, vorgenommen werden. Bei Ausfall einer Instanz wird eine Anfrage nach Überschreitung des Zeitlimits an einen replizierten Namensverwalter gerichtet. Durch die Zuordnung einer Bewertungsfunktion zu verschiedenen Namensverwalterpaaren kann zusätzlich eine Laufzeitoptimierung vorgenommen werden, indem jeweils der am günstigsten bewertete, z.B. der am besten erreichbare Namensverwalter zuerst kontaktiert wird. Dies führt zum Vorhalten von Referenzen möglichst günstiger Namensverwalter.
5.2.2.3 Rekonfigurieren des Verwalternetzes
Fällt im Verwalternetz ein Namensverwalters aus, der nicht durch einen anderen Namensverwalter repliziert wird und daher nicht ersetzt werden kann, so besteht die Gefahr der Partitionierung des Verwalternetzes. Die in Kapitel 3 vorgestellte dynamische Konfigurierung des Verwalternetzes ermöglicht es jedoch, die Verwalterhierarchie zu rekonfigurieren, um den Ausfall von Namensverwaltern zu kompensieren. Abbildung 5.9 zeigt die einzelnen Phasen des Rekonfigurierens.
Fällt im Verwalternetz ein übergeordneter Namensverwalter ki aus und kann dieser nicht durch einen replizierenden Namensverwalter krep ersetzt werden, so wird von den im Verwalternetz direkt untergeordneten Namensverwaltern ki+1 die Reorganisation des Verwalternetzes veranlaßt. Dazu muß zunächst, sofern erreichbar, die Wurzel der Verwalterhierarchie kontaktiert werden, um für die untergeordneten Namensverwalter ki+1, wie bei der Konfigurierung des Verwalternetzes, einen neuen übergeordneten Namensverwalter ki-1 zu bestimmen.
In der Reorganisationsphase wird die Konfigurations- und Navigationsinformation der untergeordneten und des neuen übergeordneten Namensverwalters ki-1 angepaßt. Besondere Behandlung erfordert die Anpassung von Navigationsinformation in Namensverwaltern, die im Verwalternetz dem ausgefallenen Namensverwalter nicht direkt übergeordnet sind, jedoch Namenseinträge mit Navigationsinformation enthalten, die auf den ausgefallenen Namensverwalter verweist. Derartige Navigationsinformation wird durch erneutes Plazieren der zugehörigen Namenseinträge im Verwalternetz wiederhergestellt, sobald ein untergeordneter Namensverwalter den Ausfall erkennt. Anschließend verweist die Navigationsinformation des neuen übergeordneten Namensverwalters ki-1 auf die untergeordneten Namensverwalter ki+1 und die Konfigurationsinformation der Namensverwalter wieder auf den jeweils übergeordneten bzw. untergeordneten Namensverwalter.
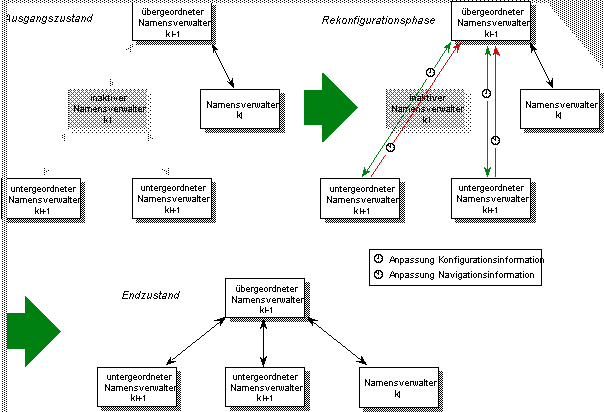
Abbildung 5.9: Rekonfigurieren des Verwalternetzes bei Ausfall eines Namensverwalters
5.2.3 Namensoperationen in Präsenz von Ausfällen
Die Funktionsfähigkeit der Namensverwaltung, insbesondere die Auflösung globaler Namen, sollte nach Möglichkeit durch Ausfälle nicht beeinträchtigt werden. Für den Anwender der Namensverwaltung sollen Ausfälle transparent bleiben (Fehlertransparenz) und ein Weiterarbeiten bei Ausfällen möglich sein. Der folgende Abschnitt beschreibt, wie eine weitgehende Fehlertransparenz bei der dynamischen Verwaltung globaler Namensräume erreicht werden kann.
5.2.3.1 Namensauflösung in Präsenz replizierter Namenseinträge
Die wichtigste Funktion einer Namensverwaltung ist die Auflösung von Namen. Verschiedene Maßnahmen der dynamischen globalen Namensverwaltung stellen sicher, daß globale Namen auch in Präsenz von Ausfällen mit hoher Wahrscheinlichkeit aufgelöst werden können.
Bereits der Ausfall eines einzelnen Namensverwalters kann die Partitionierung des Verwalternetzes bewirken, wenn nicht zusätzliche Maßnahmen getroffen werden. Um den Ausfall eines einzelnen Verwalters zu kompensieren, werden in der dynamischen globalen Namensverwaltung Verwalter derselben Hierarchiestufe im selben Netzwerkbereich repliziert. Die Auflösung globaler Namen kann daher bei Ausfällen gegebenenfalls auf das Replikat des Namensverwalters zurückgreifen (vgl. Abschnitt 5.2.2.2).
Auch wenn Namensverwalter nicht repliziert sind, besteht die Möglichkeit, inaktive Verwalter in der Navigationsphase der Namensauflösung durch vorgehaltene Namenseinträge mit Navigationsinformation auf den übernächsten Namensverwalter in der Verwalterhierarchie zu umgehen. Derartige Einträge werden durch das Vorhalten von Namenseinträge mit Navigationsinformation für aufgelöste Teilnamen im zuletzt kontaktierten Namensverwalter bereitgestellt (vgl. Abschnitt 5.1.3).
Eine zusätzliche Maßnahme ist das Replizieren von Namenseinträgen auf dem Pfad von primären Namensverwalter zur Wurzel der Verwalterhierarchie. Bei der Partitionierung des Verwalternetzes kann so sichergestellt werden, daß initiierende Namensverwalter über den Namen Objekte auf primären Namensverwaltern in derselben Partition erreichen können.
Sofern der Namensverwalter an der Wurzel der Verwalterhierarchie erreichbar ist, kann beim Ausfall übergeordneter Namensverwalter die Orientierungsphase der Namensauflösung die Wurzel der Verwalterhierarchie auch direkt kontaktieren, um inaktive Bereiche des Verwalternetzes zu übergehen. Ist der oberste Namensverwalter erreichbar, kann der Zusammenhang des Verwalternetzes durch Rekonfigurieren wiederhergestellt werden.
5.2.3.2 Registrieren von Namen in Präsenz von Ausfällen
Partitionen sind die Hauptschwierigkeit in einer Systemumgebung mit Datenreplikationen. Es gibt viele Möglichkeiten der Partitionierung, z.B. durch Netzwerkfehler, Pufferüberlauf, Wartung, usw. Replikation hingegen ist aus Gründen der Verfügbarkeit, der Effizienz und der Zuverlässigkeit unverzichtbar. Somit stellt sich die Frage, ob replizierte Namenseinträge während der Partitionierung des Verwalternetzes Änderungen erfahren dürfen. Die Antwort heißt ja, denn andernfalls sinkt die Verfügbarkeit des Namensdienstes. Außerdem ist die Wahrscheinlichkeit, daß bei Änderungen Konflikte entstehen, gering. Sie verlangen jedoch eine Koordinierung, denn die Konsistenz und die Bewahrung aller Änderungen muß stets gewährleistet sein. Umfangreiche Forschungen wurden auf diesem Gebiet insbesondere von Popek [Popek, 81] unternommen.
Das Registrieren neuer Namenseinträge in Präsenz von Ausfällen darf im gesamten Namensraum nicht zu Duplikaten von Namenseinträgen führen. Die Eindeutigkeit der Namenseinträge kann sichergestellt werden, indem bei Partitionierung des Verwalternetzes das Registrieren neuer Einträge gänzlich unterbunden wird. Bei genauerer Betrachtung läßt sich jedoch feststellen, daß neue Namen dennoch problemlos registriert werden können, sofern
· sie in Kontexten enthalten sind, die in erreichbaren Teilen des Verwalternetzes verwaltet werden.
· die Namensbasen inaktiver oder nicht erreichbarer Namensverwalter bei der Registierung neuer Namen nicht von Änderungen betroffen sind.
Diese beiden Bedingungen erhalten die Konsistenz der Namenseinträge im Verwalternetz. Wird hingegen erlaubt, neue Namen in Replikaten von Namensverwaltern in isolierten Partitionen anzulegen, so ist offensichtlich, daß dies einen tiefen Einschnitt in die Konsistenzbedingungen der dynamischen globalen Namensverwaltung und einen temporären Verzicht auf die Eindeutigkeit von Namenseinträgen bedeutet. Einerseits können Namenseinträge mit denselben Namen für unterschiedliche Objekte angelegt werden, andererseits können in isolierten Partitionen gleichzeitig dieselben Kontexte erzeugt werden, so daß auch die Navigationsinformation nicht mehr eindeutig ist.
Sobald der inaktive Verwalter wieder verfügbar wird oder die zuvor separierten Replikate eines Namensverwalters wieder zueinander in Verbindung treten, erfordert das unabhängige Registrieren neuer Einträge in Replikaten von Namensverwaltern den Abgleich der Namenseinträge und das Vereinigen der Namensraumpartitionen. Ein mögliches Verfahren hierzu wird im nächsten Abschnitt vorgestellt.
Die Replikation von Namen erhöht die Ausfallsicherheit des Systems, wobei insbesondere in einer dynamischen Namensverwaltung ein zusätzlicher Aufwand zur Konsistenzerhaltung der Namenseinträge in Kauf genommen werden muß.
5.3 Konsistenz globaler Namenseinträge
Um die Konsistenz globaler Namensverwaltungen zu diskutieren, ist es zunächst erforderlich, den Konsistenzbegriff für Namenseinträge zu präzisieren. Die Konsistenzbedingungen, die zu erfüllen sind, um die Auflösung von Namenseinträgen im hierarchischen Namensraum zu gewährleisten, wurden bereits in Kapitel 3 und 4 aufgestellt. Hierbei wurde zwischen Konsistenzbedingungen für die Konfigurationsinformation der Namensverwalter und für Namenseinträge und Navigationsinformation unterschieden.
Die Konsistenz von Namenseinträgen kann u.a. durch die parallele Ausführung konkurrierender Namensoperationen wie Registrieren und Löschen verletzt werden. Die Gewährleistung der einzelnen in Kapitel 4 aufgestellten Konsistenzbedingungen für Namenseinträge erfordert unterschiedlichen Aufwand. Während die Bedingung der Majorisierung lokal ohne Interaktion mit anderen Namensverwaltern zu erfüllen ist, erfordern die Existenz und die Eindeutigkeit die konsistente Ausführung globaler Namensoperationen.
Vorgehaltene und replizierte Namenseinträge erhöhen die Gefahr von Inkonsistenzen zusätzlich. Durch die Einführung vorgehaltener und replizierter Namenseinträge wird der Konsistenzbegriff für Namenseinträge erweitert. Insbesondere die eindeutige Zuordnung von Namenseinträgen zu Namensverwaltern ist nicht mehr zwingend notwendig. Allerdings kommt in diesem Fall als notwendige Bedingung hinzu, daß alle Kopien von Namenseinträgen übereinstimmen, d.h. auf dasselbe Objekt verweisen müssen, oder daß stets auf den aktuellen Namenseintrag zugegriffen wird. Der Ausfall von Namensverwaltern und die Partitionierung des Verwalternetzes stellen ein weiteres Problem dar, dessen Auswirkungen auf die Konsistenz der dynamischen globalen Namensverwaltung im folgenden diskutiert werden.
5.3.1 Synchronisation konkurrierender Namensoperationen
Konkurrenzsituationen können in Namensverwaltungen prinzipiell sowohl global als auch lokal auftreten. Dabei stellt sich zunächst die Frage, welche Namensoperationen synchronisiert werden müssen, da sie die Konsistenzbedingungen für Namenseinträge in den lokalen Namensbasen oder im globalen Namensraum verletzen können. In den folgenden Abschnitten werden diese Situationen identifiziert und Methoden zu deren Behandlung aufgezeigt.
5.3.1.1 Synchronisation lokaler Namensoperationen
Eine Grundvoraussetzung für die Konsistenz der Namensbasen ist, daß die einzelnen Operationen zum Anlegen und Löschen von Namenseinträgen atomar ausgeführt werden und nicht unterbrechbar sind. Andernfalls können Referenzen auftreten, die ins Leere weisen oder gelöschte Einträge referenzieren[1]. Um die Konsistenz von Namenseinträgen zu erhalten, können für die Realisierung atomarer Namensoperationen Datenbanktransaktionen herangezogen werden. Vorschläge hierzu finden sich bereits in [Kohler, 81] und [Lapson, 81]. Zuverlässige Datenspeicherung ist hingegen nicht immer erforderlich. Diese wird beispielsweise durch die Architektur und die Funktionen des COSINE Name Servers [Barker, 91] unterstützt.
Um Wettstreitsituationen und damit verbundene Inkonsistenzen zu vermeiden, gehen lokale Namensverwalter der dynamischen globalen Namensverwaltung bei der Registrierung und beim Löschen von Namenseinträgen streng sequentiell vor. Konflikte durch konkurrierende Änderungen sind in der aktuellen Implementierung nur in Form von Lösch- und Registrierungsoperationen möglich und können daher leicht erkannt werden.
Es genügt jedoch nicht, nur den Zugriff auf einzelne Namenseinträge zu sequentialisieren, da die Konsistenz hierarchischer Namen von mehreren Einträgen abhängt. Konfliktbehaftet ist daher auch das lokale Registrieren und Löschen hierarchischer Namen. Wird beispielsweise ein Namenseintrag für einen Kontext gelöscht, in dem gerade ein neuer Name registriert wird, so kann der neue Namenseintrag einen Verweis auf einen nicht mehr existierenden Kontext enthalten. Neben dem Löschen können die Konsistenzbedingungen für Namenseinträge in der dynamischen globalen Namensverwaltung auch durch das konkurrierende Registrieren desselben Namens für unterschiedliche Objekte verletzt werden. Somit wird deutlich, daß auch lokale zusammengesetzte Namensoperationen zu synchronisieren sind. Da die lokale Ausführung von Namensoperationen verhältnismäßig wenig Zeit in Anspruch nimmt, kann lokal die Synchronisation sehr effektiv durch Sequentialisierung erreicht werden. Problemlos parallel zu bearbeiten ist knotenintern nur die Auflösung hierarchischer Namen.
5.3.1.2 Synchronisation verbundweiter Namensoperationen
Innerhalb eines Rechnerverbundes mit Broadcast-Option können Namenseinträge konsistent gehalten werden, indem jeder Namensverwalter neue Einträge sofort zur Reservierung in die lokale Namensbasis aufnimmt. Konkurrierende Registrierungen und eine Verletzung der Eindeutigkeit von Namen werden innerhalb des Broadcast-Bereichs erkannt, indem der primäre Namensverwalter an jeden Namensverwalter im Bereich eine Anfrage richtet (vgl. Name Binding in AppleTalk [Apple, 90]). Existiert der Name bereits oder kollidiert die Registrierung mit einer gleichzeitig von einem anderen Namensverwalter initiierten Registrierung desselben Namens, so wird der Konflikt erkannt und der Vorgang abgebrochen. Im Falle einer konkurrierenden Registrierung wird die lokale Reservierung entfernt und nach einer zufälligen Zeit wiederholt, so daß sich eine der Registrierungen durchsetzen wird.
Um die Auflösung von Namen zu beschleunigen und Mehrdeutigkeiten im Rechnerverbund bei Ausfall eines Namensverwalters zu vermeiden, werden Namenseinträge in den Namensverwaltern des Broadcast-Bereichs repliziert. Replikate von Namenseinträgen können sofort bei der Prüfung der Eindeutigkeit in die Namensbasen der Namensverwalter aufgenommen werden. In diesem Fall ist die Synchronisation konkurrierender Registrierungen durch Zeitstempel- oder Abstimmungsverfahren unerläßlich, da andernfalls die Möglichkeit besteht, daß Replikationen unterschiedlicher Namenseinträge gehalten werden.
5.3.1.3 Synchronisation globaler Namensoperationen
Für die Konsistenz globaler Namensräume ist die Synchronisation der Namensoperationen in lokalen Namensverwaltern notwendig, jedoch nicht hinreichend. Selbst bei Sequentialisierung der lokalen Namensoperationen kann es immer noch auf globaler Ebene zu Wettstreitsituationen kommen. Der Vorgang der Auflösung ist dabei wiederum relativ unproblematisch. Globale Inkonsistenzen können beim Löschen und beim Registrieren von Namenseinträgen auftreten.
Da Namen in der dynamischen globalen Namensverwaltung syntaxgesteuert plaziert werden, beziehen sich konkurrierende Registrierungen stets auf denselben Namensverwalter. Hier können Konflikte jedoch durch Sequentialisierung aufgelöst werden. Einzige Ausnahme bilden Namenseinträge, die sich nicht in vorhandene Kontexte einordnen lassen und daher an alle Namensverwalter auf dem Pfad von Wurzel der Verwalterhierarchie zum primären Namensverwalter propagiert werden. Hier können Konflikte auftreten, wenn derselbe Name gleichzeitig von einem zweiten Namensverwalter registriert wird, da beide Verwalter in der Orientierungsphase der Registrierung keinen entsprechenden Eintrag im Namensraum lokalisiert haben.
Dem Registrieren von Namenseinträgen geht eine Phase zur syntaxgesteuerten Plazierung voraus, die als eine Art Reservierung verstanden werden kann. Die geschilderte Konkurrenzsituation kann somit vermieden werden, da im obersten Namensverwalter beim Plazieren eine Reservierung für den neuen Eintrag vorgenommen wird, noch bevor er im primären Namensverwalter plaziert ist (vgl. Abbildung 5.10). Ein konkurrierender Versuch zum Plazieren eines Eintrags wird somit in der Orientierungsphase erkannt und abgebrochen. Eine der konkurrierenden Registrierungen wird sich dabei durchsetzen. Voraussetzung hierfür ist, daß das Überprüfen auf das Vorhandensein des Namenseintrags und das Plazieren innerhalb eines Namensverwalters atomar erfolgt.
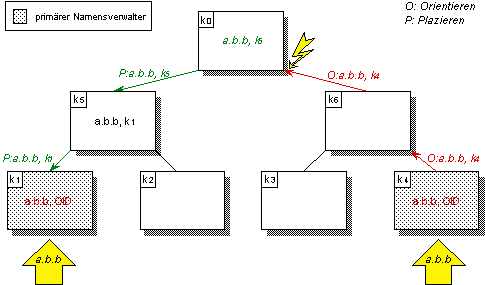
Abbildung 5.10: Beispiel einer konfliktären Registrierung von Namen
Konkurrierende Löschoperationen für einen Namenseintrag können sehr einfach aufgelöst werden, da sich durch die lokale Sequentialisierung im Namensverwalter eine Operation durchsetzen wird.
Eine eingehendere Behandlung hingegen muß das konkurrierende Registrieren und Löschen globaler Namenseinträge erfahren. Übergeordnete Kontexteinträge werden nur dann gelöscht, wenn alle bis auf einen enthaltenen Eintrag entfernt wurden (vgl. Kapitel 4). Das Löschen hat, ähnlich dem Hinzufügen von Namen, somit i.d.R. nur lokale Auswirkungen. Im Normalfall sind somit konkurrierende Registrierungs- und Löschoperationen ein lokales Problem. Schwierigkeiten treten jedoch auf, wenn ein neuer Eintrag syntaxgesteuert plaziert wird und gleichzeitig ein Löschvorgang initiitert wurde, der genau die Kontexte und die Navigationsinformationen, die zur gewählten Plazierung geführt haben, entfernt. Die kritische Phase dabei ist der Zeitpunkt, in dem sich der Löschvorgang mit dem Plazieren kreuzt. Um diese Situation aufzulösen, bietet sich folgendes Vorgehen an:
Wurde ein Eintrag zur Plazierung an einen Namensverwalter geleitet und erkennt dieser, daß der Kontext im ausgewählten Namensverwalter nicht mehr vorhanden ist, so wird der zu registrierende Namenseintrag an den übergeordneten Namensverwalter propagiert. Hierbei können in übergeordneten Namensverwaltern immer noch Kontexte vorhanden sein, die den Namen enthalten. Dieses Vorgehen löst zwar den beschriebenen Konflikt, dennoch könnte der Eintrag u.U. günstiger plaziert werden, wenn nach dem Löschen der neue Eintrag keine ähnlichen Einträge mehr auf dem Pfad zur Wurzel besitzt, indem der Namenseintrag vom primären Namensverwalter zur Wurzel propagiert wird.
Eine Reduzierung des Nachrichtenaufwands bei konkurrierenden Registrierungs- und Löschoperationen kann zudem erzielt werden, wenn Kontexte nicht sofort entfernt werden, sondern erst nach einer kurzen Verzögerung, die länger ist als die Zeit für das Registrieren. Die Verzögerung wird in jedem Namensverwalter angewandt, den die Löschoperation erreicht. Hierdurch wird verhindert, daß durch den Löschvorgang die Navigationsinformation in den Namensverwalteren präzisiert wird und anschließend sofort wieder verallgemeinert werden muß, was einen erheblichen Nachrichtenfluß zur Folge hätte. Inbesondere bei Änderungsoperationen auf Namenseinträgen, die als Löschen und erneutes Registrieren gehandhabt werden, macht sich dieses Vorgehen positiv bemerkbar.
Die Problematik des Registrierens und Löschens von Namenseinträgen bei replizierten Namensverwaltern bzw. in Präsenz von Ausfällen wird in Abschnitt 5.3.1.4 bzw. 5.2.3 behandelt.
5.3.1.4 Migration globaler Namenseinträge
Hierarchisch strukturierte Namensverwaltungen, wie X.500 [CCITT/ISO, 88] oder das Domain Name System [Mockapetris, 84a], unterstützen keine Migration benannter Objekte im verteilten System. Sofern die Netzwerkschicht der zugrundeliegenden Netzwerkarchitektur keine Migrationsunterstützung bietet (z.B. Mobile IP), ist die Änderung des Namens oder zumindest aber die manuelle Änderung der Verwaltungsinformation in den zuständigen Namensverwaltern erforderlich. Bei zunehmender Mobilität globaler Objekte bedeutet dies einen erheblichen Aufwand. Einzelne Verzeichnisdienste besitzen daher Erweiterungen, die ein Nachführen von Verweisen auf Namenseinträge bei der Migration benannter Objekten vornehmen. Derartige Verfahren sind jedoch nicht für hoch mobile Systeme konzipiert und erfordern einen hohen zusätzlichen Aufwand, so daß sie nur für sporadische Migrationen geeignet sind.
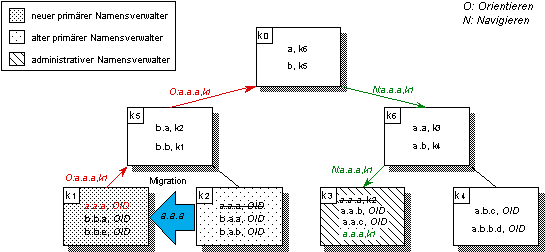
Abbildung 5.11: Syntaxgesteuerte Plazierung bei der Migration von benannten Objekten
In der dynamischen globalen Namensverwaltung ist die Migration benannter Objekte und der zugehörigen Namenseinträge durch Löschen und Registrieren realisiert. Migriert ein Objekt, so werden die Namenseinträge zunächst im primären und im administrativen Namensverwalter gelöscht und anschließend im Zielknoten erneut global registriert. Übergeordnete Kontexte und deren Namensverwalter sind von der Migration nur dann betroffen, wenn der Name des migrierenden Objekts der einzige im Kontext ist. Der Namenseintrag des migrierenden Objekts wandert syntaxgesteuert mit einem Verweis auf den neuen primären Namensverwalter zu seinem ursprünglichen administrativen Namensverwalter und kann bei Anfragen dort wie gewohnt lokalisiert werden (vgl. Abbildung 5.11).
5.3.2 Konsistenzerhaltung vorgehaltener Namenseinträge
Replikationen verschärfen die Problematik der Konsistenz von Namenseinträgen. Da vorgehaltene Namenseinträge nicht von deren primären oder administrativen Namensverwaltern kontrolliert werden, verursacht jede Änderung eines Namenseintrags eine Inkonsistenz in vorgehaltenen Namenseinträgen. Der folgende Abschnitt beschreibt Maßnahmen zur Konsistenzerhaltung vorgehaltener Namenseinträge in globalen Namensverwaltungen.
5.3.2.1 Konsistenz durch Indirektion über vorgehaltene Namenseinträge
Um dem Problem der Konsistenz vorgehaltener Namenseinträge zu begegnen, werden in vielen globalen Namensverwaltungen vorgehaltene Namenseinträge als Hinweise auf den zuständigen Namensverwalter verstanden [Terry, 87]. Der Zugriff erfolgt indirekt über den Namensverwalter, niemals direkt über den Objekt-Bezeichner selbst. Der initiierende Namensverwalter ist stets gehalten, den Namensverwalter zu kontaktieren, um den Objekt-Bezeichner zum Namen zu ermitteln und die Konsistenz zu prüfen.
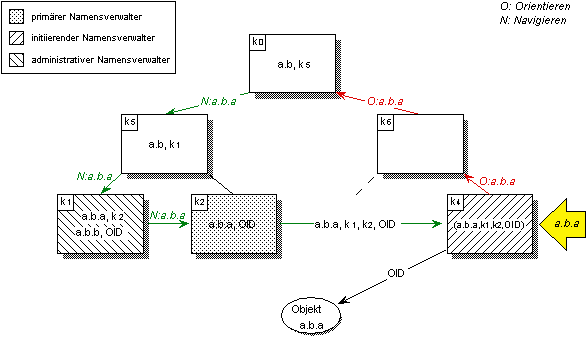
Abbildung 5.12: Vorhalten von Verweisen auf den administrativen und primären Namensverwalter
Die dynamische globale Namensverwaltung verwendet ein Verfahren zum Vorhalten von Namenseinträgen, wobei vorgehaltene Namenseinträge den Objekt-Bezeichner des an den Namen gebundenen Objekts, sowie einen Verweis auf den primären und auf den administrativen Namensverwalter enthalten (vgl. Abbildung 5.12).
Beim Zugriff auf ein Objekt über einen vorgehaltenen Namenseintrag wird zunächst versucht, das Objekt über den Objekt-Bezeichner zu erreichen. Sofern Objekt-Bezeichner global eindeutig vergeben werden, kann die Gültigkeit des vorgehaltenen Objekt-Bezeichners geprüft werden. Gelingt dies nicht, so wird der primäre Namensverwalter kontaktiert, um den aktuellen Objekt-Bezeichner zum Namen zu ermitteln. Bleibt auch dies ohne Erfolg, so wird schließlich der vorgehaltene administrative Namensverwalter kontaktiert, um den primären Namensverwalter des Namens zu ermitteln (vgl. Abbildung 5.13). Kann ein Objekt über den vorgehaltenen Namenseintrag nicht ermittelt werden, so wird eine globale Auflösung notwendig. Führt diese zum Erfolg, so wird der vorgehaltene Namenseintrag angepaßt. Verweisen vorgehaltene Namenseinträge auf gelöschte Namenseinträge und können sie nicht verifiziert werden, so werden sie als ungültig markiert und bei Gelegenheit entfernt.
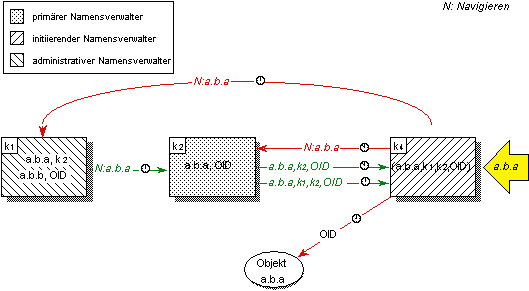
Abbildung 5.13: Direkter und indirekter Objektzugriff über vorgehaltene Namenseinträge
Die Namensauflösung mit Hilfe indirekter, vorgehaltener Referenzen erweist sich als sehr effektiv, da lokale Änderungen i.d.R. keine globalen Veränderungen im Namensraum implizieren und vorgehaltene Namenseinträge bei lokalen Änderungen ihre Gültigkeit behalten. Wurde der vorgehaltene Name lokal an ein anderes Objekt gebunden, so kann über die vorgehaltene Referenz auf den primären Namensverwalter der neue Objekt-Bezeichner ermittelt und vorgehalten werden. Bei der Migration benannter Objekte ändert sich der primäre Namensverwalter, d.h. der vorgehaltene Verweis auf den primären Namensverwalter wird ungültig, der administrative Namensverwalter bleibt jedoch derselbe, sofern nicht alle Einträge des übergeordneten Kontexts entfernt wurden.
5.3.2.2 Begrenzung der Lebenszeit vorgehaltener Namenseinträge
In der dynamischen globalen Namensverwaltung werden inkonsistente vorgehaltene Namenseinträge beim Zugriff erkannt und aktualisiert. Um weitere Inkonsistenzen in den vorgehaltenen Einträgen zu vermeiden, werden die verschiedenen Indirektionsstufen beim Objektzugriff über vorgehaltene Namenseinträge zusätzlich jeweils getrennt mit einem Zeitlimit (time-to-live value, TTL) versehen, der ihre Gültigkeit begrenzt. Ein vorgehaltener Namenseintrag wird gelöscht, sobald das Zeitlimit verstrichen ist. Bestimmt wird das Zeitlimit vom Erzeuger des Namenseintrags. Die TTL eines Kontexts wird auf das Maximum der TTLs der enthaltenen Namenseinträge festgesetzt. Die TTL eines häufig modifizierten Objekts kann auf die durchschnittliche Lebensdauer des Objekts begrenzt werden.
Weiterentwickelte Strategien zur Konsistenzerhaltung vorgehaltener Namenseinträge können u.a. folgende Faktoren berücksichtigen:
• Das Datum des letzten erfolgreichen Zugriffs, weniger das Erstellungs- und Modifikationsdatum.
• Das Verhältnis zwischen schreibenden und lesenden Zugriffen auf den Namenseintrag. Einträge, die oft gelesen aber selten geändert werden, eignen sich gut für das Vorhalten und eine weit gestreute Replikation. Einträge, die häufig modifiziert werden, sind dafür weniger geeignet. In der dynamischen globalen Namensverwaltung kann dieses Verhältnis auf die Registrierungszeit zurückgeführt werden, da Änderungen als Kombination von Lösch- und Registrierungsoperationen realisiert werden.
• Die ältesten vorgehaltenen Einträge können gelöscht werden, wenn der beschränkte Speicherplatz im Cache zu voll wird und neue Einträge hinzukommen sollen.
• Längere hierarchische Namen erhalten eine kürzere TTL als kürzere Namen. Durch diese Strategie werden übergeordnete Kontexte länger vorgehalten als untergeordnete.
[AL3]Wie gezeigt, kann durch einfache aber effektive Methoden wie Zeitlimits und indirekte Referenzen die Konsistenz vorgehaltener Namenseinträge hergestellt werden. Aufwendiger hingegen ist die Konsistenzerhaltung aktiv replizierter Namenseinträge und ganzer replizierter Namensverwalter, wie der folgende Abschnitt zeigt.
5.3.2.3 Überwachung von Namensbeziehungen
Ein schwerwiegendes Problem ist die Änderung von Namen und Bindungen, die sich auf der Anwendungsebene in Benutzung befinden. Als Beispiel sei hier an Uniform Resource Locators (URL) [Berners-Lee, 94] in WWW-Seiten erinnert, die ungültig werden, sobald sich der Name oder der Speicherort einer referenzierten Seite ändert.
Abhilfe schafft hier die Überwachung von Namensbeziehungen, wobei Klienten die Benutzung von Namen beim zugehörigen Namensverwalter explizit an- und abmelden. So ist es möglich, einen Klienten zur Laufzeit von der Änderung eines Namens oder des gebundenen Objekts zu informieren. Dies kann bei entsprechenden Vorkehrungen in der Laufzeitbibliothek des Klienten anwendungstransparent geschehen.
Eichler [Eichler, 88] beschreibt für
den Namensdienst der Interprogrammebene (vgl. Kapitel
2) sechs Operationen zur Abfrage und Manipulation des Namensraums, die
in Verbindung mit der Überwachung der Namensnutzung ein flexibles
Instrumentarium zur Namensverwaltung bieten. Die Operationen sind frei von
Verwaltungsoperationen der Namenshierarchie und bilden die Grundbausteine für
höhere Namenskonzepte.
|
Abfragen: |
|
|
Locate
(name,
server) |
Ermitteln des Namensverwalters (server), der den gesuchten Namen (name) und mögliche weitere aus dessen Kontext bereitstellt. |
|
Attach
(server,
name, client, data) |
a) Ermitteln der Daten (data), die beim Namensverwalter (server) unter einem Namen (name) abgelegt sind. b) Registrierung der Beziehung zwischen Klient (client) und Namen (name). |
|
Detach
(server,
name, client) |
Abmelden der Beziehung zwischen Klient (client) und Namen (name) beim Namensverwalter (server). |
|
Änderungen: |
|
|
Assign
(server,
name) |
Einrichten eines Namens (name) beim gegebenen Namensverwalter (server), Benachrichtigung von Klienten mit Vormerkung auf die Namensbeziehung (Attach-Befehl mit Namen, der mit Assign-Befehl gemeldet wird). |
|
Remove
(server,
name) |
Löschen des Namens (name) bei gegebenem Namensverwalter (server), Benachrichtigung von Klienten mit laufender Namensbeziehung (Attach-Befehl). |
|
Replug
(server,
name, data) |
Ersetzen von Daten (data) unter definiertem Namen (name) beim Namensverwalter (server), Benachrichtigung von Klienten mit laufender Namensbeziehung. |
Klienten, die den Attach-Befehl für einen manipulierten Namen gegeben haben, werden über die Art der Manipulation benachrichtigt. Beim Detach-Befehl wird die Vormerkung zur Benachrichtigung wieder aufgehoben. Die Semantik der gegebenen Operationen ermöglicht es, aus Klientensicht die Identität von Namen und zugehörigen Objekt-Identifikationen zu ermitteln. Auf der Basis dieser Identität lassen sich verschiedene Programmkonzepte verwirklichen. Insbesondere können damit Mechanismen zur Indirektion auf Namensebene eingeführt werden, die z.B. den Austausch von Diensten zur Laufzeit und höhere Migrationskonzepte ermöglichen. Zusätzlicher Aufwand im Systemkern ist dazu nicht erforderlich.
Die Überwachung von Namensbeziehungen kann auch eingesetzt werden, um vorgehaltene oder replizierte Namenseinträge im Änderungsfall zu aktualisieren. Die generelle Verwendung eines derartigen Aktualisierungsmechanismus bedeutet jedoch einen erheblichen Verwaltungsaufwand und erhöht die Komplexität der Namensverwaltung, so daß sie allgemein keine Verwendung findet.
5.3.3 Konsistenzerhaltung replizierter Namenseinträge
In einer dynamischen Namensverwaltung mit häufigen Änderungen der Namenseinträge müssen die Namensverwalter Zugriff auf konsistente Kopien replizierter Namenseinträge haben. Die Konsistenzerhaltung aller Kopien von Namenseinträgen stellt jedoch ein schwieriges Problem dar, das in der Literatur als „mutiple copy update“ bekannt ist und eine der zentralen Fragen im Entwurf verteilter Systeme darstellt.
Replikationen haben den Nachteil, daß sie die Komplexität eines Systems erhöhen und aufwendige Verfahren für die Propagierung von Änderungen und zur Konfliktbehebung bei Inkonsistenzen verlangen. Besteht eine geringe Wahrscheinlichkeit des Auftretens von Konflikten, so bieten sich zur Konsistenzerhaltung sog. optimistische Verfahren an. Sind Konflikte hingegen sehr wahrscheinlich, besitzen pessimistische Verfahren Vorteile (vgl. Abbildung 5.14).
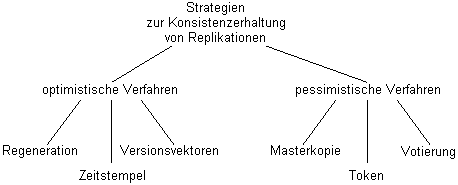
Abbildung 5.14: Mögliche Verfahren zur Erhaltung der Konsistenz von Namenseinträgen
Allgemeine Algorithmen für die konsistente Verwaltung replizierter Daten treffen keine Annahmen über die Art der verwalteten Daten. Daher basieren verschiedene Vorschläge für verteilte Systeme auf dem Verfahren des „weigthed voting“ [Gifford, 79]. Die Leistungsfähigkeit derartiger Verfahren kann unter Berücksichtigung der speziellen Eigenschaften von Namensverzeichnissen optimiert werden (vgl. [Daniels, 83]). Eine zusätzliche Verbesserung wird durch die Einführung höherer Nebenläufigkeit erreicht, indem die Menge der in einem Verzeichnis gespeicherten Namenseinträge dynamisch partitioniert und zu jeder Partition eine Versionsnummer gespeichert wird.
In neueren Namensverwaltungen basieren viele Algorithmen für replizierte Daten auf der Annahme, daß die Verwalter miteinander kommunizieren können. In lokalen Netzwerken kann die Kommunikation beinahe ohne jede Einschränkung stattfinden, während bei Wählverbindungen u.U. nur die Möglichkeit besteht, Daten zu bestimmten Zeiten oder mit bestimmten Verwaltern abzugleichen.
Globale Namen weisen eine große Stabilität auf, d.h. Namen und ihre Bindungen zu Objekten unterliegen kaum Änderungen. Aus diesem Grund können globale Kontexte ohne großen Aufwand als Replikate gehalten werden. Diese Replikate liegen im einfachsten Fall in Form lokal gewarteter Datenbasen oder Konfigurationsdateien vor (DECNet, TCP/IP). Nach einem Vorschlag von Lampson [Lampson, 86] werden die Verwalter replizierter Kontexte ringförmig verkettet, um den Aktualisierungsvorgang zu automatisieren. Multicast-Eigenschaften kommen nicht zur Anwendung, da sie in globalen Netzwerken nicht vorausgesetzt werden können. Die Konsistenz replizierter Kontexteinträge kann in einem Aktualisierungsprotokoll anhand von Zeitmarken geprüft und, falls erforderlich, hergestellt werden. Das Protokoll muß dabei den Forderungen nach Idempotenz und Vertauschbarkeit von Aktualisierungsschritten genügen.
Zur Behandlung von Änderungen an der Namensbasis sind nun jedoch zusätzliche Mechanismen erforderlich, um die replizierten Namensverwalter konsistent zu halten. Das Ziel ist dabei, möglichst auch bei einzelnen Namensverwalterausfällen oder Netzwerkpartitionierungen Änderungen replizierter Namenseinträge durchführen zu können.
Eine Möglichkeit dafür sind Abstimmungsverfahren, bei denen zuerst eine Mehrheit der Replikate des Namensverwalters einer Änderung zustimmen muß, bevor diese schließlich durchgeführt werden kann (Voting). Dadurch wird garantiert, daß auch bei Netzwerkpartitionierung keine verschiedenen Versionen der replizierten Daten in den jeweiligen Partitionen entstehen können; höchstens eine der Partitionen kann eine Änderung erfolgreich durchführen und mindestens ein Namensverwalter davon war zwangsläufig an der vorhergehenden Mehrheitsabstimmung und Änderung beteiligt. Verfahren dieser Klasse werden zum Beispiel in [Oki, 88], aber auch in vielen anderen Arbeiten beschrieben. Diese Verfahren sind generell für replizierte Namensverwalter anwendbar; allerdings ist ihre garantierte strenge Datenkonsistenz nicht unbedingt immer erforderlich. Eine Abschwächung der Konsistenzgarantie ist möglich, indem inkonsistente Zwischenzustände toleriert werden, aber trotzdem garantiert wird, daß schließlich ein global konsistenter Zustand erreicht wird. Ansätze dieser Klasse sind zum Beispiel in [Oppen, 81] und [Birell, 82] beschrieben.
Verfahren mit schwacher Konsistenzgarantie erlauben lokale Änderungen der Daten eines Namensverwalters, ohne dabei sofort auch alle anderen Replikate konsistent ändern zu müssen. Dadurch kann eine Änderung einem anfordernden Klienten schneller bestätigt und auch dann durchgeführt werden, wenn keine Mehrheit der replizierten Namensverwalter verfügbar ist. Falls der initiierende Namensverwalter später denselben Namensverwalter nach einem geänderten oder eingefügten Namen befragt, erhält er die korrekte Antwort. Andere Namensverwalter können zwar eventuell für einen kurzen Zeitraum veraltete Daten liefern, dies wird aber allgemein akzeptiert und von der Anwendung erkannt.
Sehr kritische Anfragen können in Ausnahmefällen auch repliziert bei mehreren Namensverwaltern abgesetzt werden. Um in Konflikt stehende, konkurrierende Änderungsanforderungen zu erkennen, wird jeder Namenseintrag mit einem Zeitstempel des Rechners versehen, der zuletzt eine Änderung darauf durchgeführt hat. Daher werden die entsprechenden Verfahren auch als Zeitstempel-basiert bezeichnet. Eine totale Ordnung der Zeitstempel wird durch Konkatenierung lokaler Zeitstempel mit einer eindeutigen Identifikation des Namensverwalters erreicht; die Identifikationen selbst sind dabei total geordnet. Die Uhren der verschiedenen Namensverwalter müssen innerhalb eines bestimmten Intervalls synchronisiert sein.
Ein Namensverwalter, der lokal eine Änderung durchgeführt hat, sendet den neuen Eintrag an seine Replikate, nachdem er dem Klienten bereits die Änderung bestätigt hat. Falls ein Replikat nicht verfügbar ist, wird die entsprechende Nachricht periodisch wiederholt. Jeder Namensverwalter führt eine eintreffende Änderung auf seiner lokalen Namensbasis durch, sofern ihr Zeitstempel aktueller ist als der Zeitstempel des eigenen Eintrags. Dadurch wird schließlich garantiert, daß alle Replikate des Namensverwalters die gleichen Änderungssequenzen vornehmen; allerdings können Anomalien auftreten, indem die gleiche Änderung gemäß der absoluten Zeit bei einem Namensverwalter k1 früher als bei einem anderen Namensverwalter k2 angefordert wurde, die Änderung von k1 aber dominiert, weil k1 eine divergierende lokale Uhr mit separater lokaler Zeit besitzt. Solche Anomalien werden jedoch toleriert, da sie zumindest keine Inkonsistenzen zwischen den Namensverwaltern hervorrufen. Zusätzlich müssen auch noch gelöschte Einträge markiert und für bestimmte Zeit als solche gespeichert werden. Ansonsten könnte eine Anforderung zum Erzeugen und späteren Löschen eines Eintrags falsch behandelt werden, falls die zugehörigen Nachrichten durch Überholen vertauscht werden. Nach einem relativ langen Timeout können die gelöschten Einträge ganz entfernt werden, wenn sichergestellt ist, daß die Nachrichtenverweilzeit kürzer als der Timeout ist [Schill, 92].
Falls im System bei schwerwiegenden Fehlerfällen Inkonsistenzen auftreten, können die Namensbasen der Replikate des Namensverwalters zusätzlich von Zeit zu Zeit aufgrund der Zeitstempel verglichen und aktualisiert werden. Dieses Verfahren sowie die Abstimmungsverfahren zeigen zwei Grenzen eines Spektrums auf, in dem noch viele weitere Verfahrensvarianten zu finden sind. So kann zum Beispiel für jeden replizierten Kontext ein primärer Namensverwalter benannt werden, an den alle Änderungsanforderungen gesendet werden müssen. Die Rolle des primären Namensverwalters kann dabei im Fehlerfall durch einen anderen Namensverwalter übernommen werden. Auf diese Weise werden Konflikte zwischen Änderungen vermieden, allerdings ist eine Erweiterung des Protokolls zur Konfigurationsverwaltung der Namensverwalter erforderlich.
5.3.4 Abgleich von Namensraumpartitionen replizierter Namensverwalter
Werden während der Partitionierung des Namensraums oder des Verwalternetzes Änderungen im Namensraum vorgenommen, die auch die jeweils anderen isolierten Partitionen des Namensraums bzw. Verwalternetzes betreffen, so ist mit Aufhebung der Partitionierung der Abgleich (Recovery) der separierten Namensräume erforderlich. Während einer Partitionierung arbeitet jede Partition unabhängig von den übrigen Teilen des Namensraums. Werden die Partitionen wieder zusammengefügt, so sorgt eine Merge-Funktion beim Vereinigen von Partitionen dafür, daß Konflikte zuverlässig erkannt werden [Popek, 81]. Die Verzeichnisse werden automatisch abgeglichen. Gelingt das nicht, so wird das Problem an eine höhere Schicht gemeldet (z.B. den Benutzer).
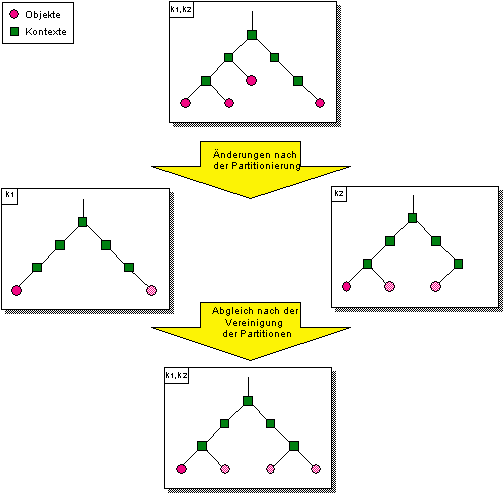
Abbildung 5.15: Änderung und Abgleich eines partitionierten Namensraums
Für den Abgleich von Partitionen desselben Namensraums wird folgende Ausgangssituation betrachtet: Der Eintrag für den Namen n befindet sich auf Namensverwalter k1 und k2. Nach einer gewissen Zeit werden k1 und k2 getrennt. Beim Zusammenfügen von Partitionen eines Namensraums können folgende zwei mögliche Situationen auftreten:
1. Der Namenseintrag für n wurde entweder auf Namensverwalter k1 oder auf k2 verändert. In diesem Fall tritt kein Konflikt auf.
2. Der Namenseintrag für n wurde sowohl auf Namensverwalter k1 als auch auf k2 verändert. In diesem Fall besteht ein Konflikt.
Konflikte beim Abgleich von Namensräumen können anhand eines Versionsvektors erkannt werden. Bei komplexen Änderungen ist dies keine triviale Aufgabe, dennoch existiert hierzu ein adäquates Verfahren [Popek, 81]. Namensoperationen haben eine einfache Semantik (Registrieren und Löschen), so daß Konflikte aufgelöst werden können. Beim Abgleich von Partitionen eines Namensraums, die unabhängig voneinander modifiziert wurden, wird schrittweise vorgegangen:
1. Die Namensverwaltung ist für die Erkennung aller Konflikte verantwortlich.
2. Die partiellen Namensräume werden automatisch abgeglichen.
3. Liegt ein Konflikt vor, so wird der Eigentümer über den Konflikt informiert, um das Problem interaktiv zu beheben.
Obwohl die Namensraumoperationen eine einfache Semantik besitzen, sind die Regeln zum Abgleich von Namensräumen nicht trivial. Das hat seine Ursache darin, daß Operationen auf einem Eintrag ausgeführt werden können, der nicht in der Partition vorhanden ist, und zum anderen ein Eintrag, der in einer Partition gelöscht wurde, während er in einer anderen verändert wurde, erhalten bleiben muß. Ist der Versionsvektor der Einträge identisch, dann ist kein Abgleich notwendig, andernfalls wird folgendermaßen verfahren:
1. Namenskonflikte werden geprüft. Für identische Namen in der Vereinigung der Namensräume müssen die Objekt-Bezeichner übereinstimmen, andernfalls werden die Namen zur Unterscheidung verändert und der Benutzer informiert.
2. Außerdem werden die Namenseinträge überprüft:
• Erscheint der Eintrag nur in einer Partition des Namensraums, so wird er übernommen.
• Wurde ein Eintrag in einem Namensraum gelöscht und im anderen nicht, so wird der Eintrag gelöscht, falls er seit dem Löschen nicht verändert wurde.
• Haben beide Namensräume einen Eintrag und einer wurde gelöscht, der andere modifiziert, dann muß der Eintrag erhalten bleiben.
• Haben beide Namensräume einen Eintrag und keiner wurde verändert, dann ist kein Abgleich erforderlich.
Dieses Vorgehen stellt die Konsistenz des Namensraums wieder her. Die Auflösung von Konflikten, hervorgerufen durch konkurrierende Modifikationen von Namenseinträgen, erfordert ein Eingreifen des Anwenders, entweder zum Zeitpunkt des Abgleichs, oder, falls temporär die Mehrdeutigkeit von Namenseinträgen geduldet werden kann, spätestens zum Zeitpunkt der Namensauflösung.
Die Konsistenzerhaltung von Namenseinträgen in der dynamischen globalen Namensverwaltung basiert auf optimistischen Verfahren zur Sicherung schwacher Konsistenz, wobei Konflikte stets beim Zugriff auf Objekte erkannt und behoben werden.